こんにちは!Dataintelligenceチームの垣内です。
毎日の売上集計や言語モデルの更新など様々な場面や用途で用いられるバッチ処理。
Microsoft Azureでバッチ処理について調べてみると、様々なサービスを使ったアーキテクチャが出てきます。
例えばAzure Functions。Azure FunctionsにはTimeTriggerという機能があり、バッチ処理を実装することができます。
しかし、この機能には実行時間の制限があるので、時間を要するデータ分析・ETL処理をするバッチ処理には不向きであるとされています。
勿論、実行したバッチ処理が予定時間内に完了しない「突き抜け」が発生する可能性が低い簡易的な処理であればAzure Functionsを選択すると良いでしょう。
今回はMicrosoft Azureにおいてバッチ処理の代表的なサービスであるAzure Batchを用いて、コンテナ化したバッチスクリプトを動かしてみたいと思います!
※本ブログでは、事前に以下の準備を済ませている事を前提に進めます。
・Microsoft Azureのアカウントがある
・Azure Container RegistryにImageをPushしている
まずはAzure Batchについて説明します。その後、設定方法や動かし方を説明していきます。
Azure Batchとは
Microsoft Azureが提供するバッチ実行サービスであるAzure Batch。その名前の通り、大量のデータを加工してデータベースに投入するETL処理の一部として使われたり、処理の並列実行に向いているサービスです。 実行時間の制限を柔軟に設定でき、様々な目的に合ったノード(仮想マシン)を選ぶことができます。
課金方式は、仮想マシン、ストレージ、ネットワークなどのリソースを使った分だけを支払う仕組みとなっています。
Azure Batchで出てくる用語
Azure Batchを動かす上で知っておくべき用語を紹介します。
ノード:仮想マシン
定義された処理内容を実行するAzureから提供されている仮想マシン(VM)の事です。 Azure BatchではLinuxのみならず、WindowsのVMも選択できます。 ノードの種類によって「CPUのコア数、メモリ容量、ノードに割り当てられるローカルファイルシステムのサイズ」が決まってきます。
選択したOSに対応しているものであれば、ノード上で .exeといった実行可能ファイルや、.cmd、.bat および PowerShell スクリプト (Windows の場合)、バイナリ、シェル、Python スクリプト (Linux の場合) などなどを実行できます。
プール:仮想マシンの集まり
アプリケーションやバッチ処理を実行するノード(仮想マシン)の集まりの事です。 大規模な割り当てや、アプリケーションのインストール、データの分散、状態の監視などに応じて、プール内のノード数を柔軟に調整させることも、処理をしない間はノードの数を減らすといったことも可能です。
プールに追加された全てのノードは一意の名前と IP アドレスが割り当てられます。 尚、ノードがプールから削除されると、OSやファイルに加えられた変更、登録したJobは失われ、割り当てられた名前とIPアドレスも解放されるようになっています。(豆知識的に覚えておくと良いでしょう!)
タスク:処理
Azure Batchにおいて設定できる一番小さな処理の単位です。 .batファイルを実行したり、ファイルを移動させる....といった処理を指定します。
ジョブ:タスクを集めてできた大きな処理
タスクの集まりの事をジョブと言います。このジョブはプールに紐づいて作成されるので、プールが削除されると紐づいているジョブとタスクも削除されます。 ジョブはTODOリストで、タスクは1つ1つのToDoであるとイメージすると良いでしょう。
ジョブでは「最大実時間の設定」と「タスク再試行の最大回数」を指定できます。 最大時間を設定すると、ジョブの実行時間が指定された最大実時間を超えた場合に、ジョブとそのすべてのタスクを強制的終了させることができます。 タスク再試行の最大回数を指定すると、タスクが失敗した完了するまで指定した回数まで再試行したり、逆に再試行を禁ずることができます。 (※再試行:タスクが失敗した場合に、もう一度実行するためにキューに置くこと。)
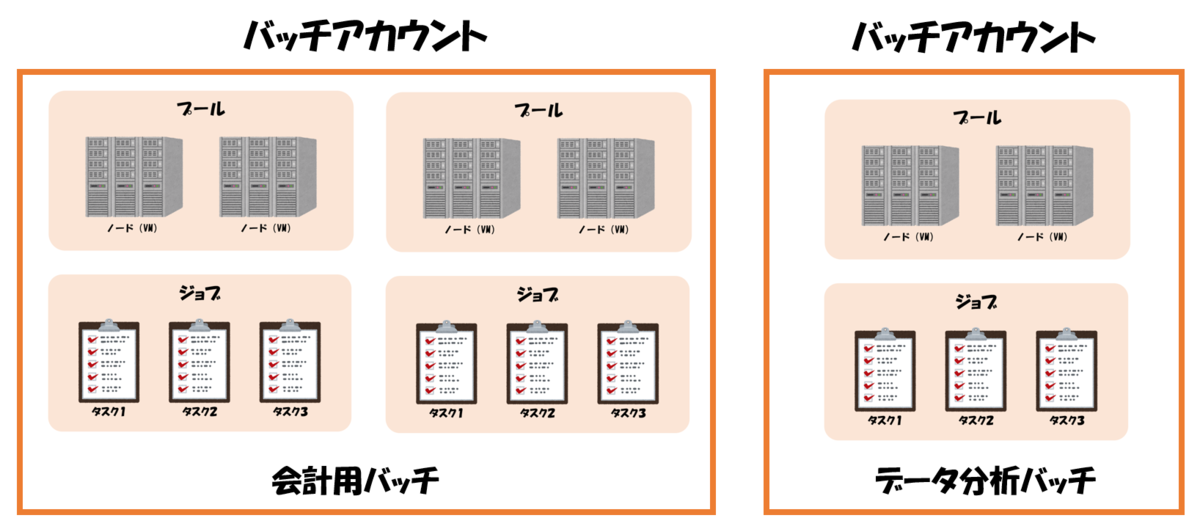
バッチアカウント:一意認識できる箱のような概念
Azure Batchでは、様々な用途に応じて多様なジョブを作ることとなります。 そのジョブが何のためのジョブか管理しやすいように、 Azure Batch内で一意に識別できるよう纏まりにしたものをバッチアカウントと言います。 イメージがわき辛いと思いますが、「システムA 用のバッチ」「システムB用のバッチ」といったように箱を用意して、どのプール(タスク)が紐づいているか整理するための考え方なのだと思ってください。 バッチアカウントでは複数のジョブを作成出来ます。
コンテナ化したバッチ処理をAzure Batchで動かす
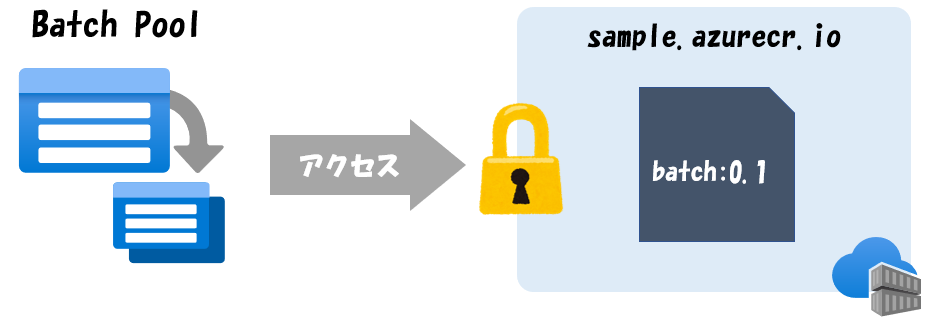
Azure Batchでコンテナを動かすためには、下の図のようにコンテナイメージが保管されているコンテナレジストリにAzure Batchがアクセスして、イメージを取得できるようにしておく必要があります。 そのためには、コンテナレジストリの接続情報が必要となります。
準備と設定
ではAzure Batchを動かすための準備と設定をしていきます。
手順は以下の通りです。
1. コンテナレジストリとイメージの準備
2. バッチアカウント作成
3. プールの作成
4. ジョブの作成とタスクの追加
コンテナレジストリとイメージの準備
Azureポータルの検索窓から「コンテナレジストリ」と検索します。すると下の図のように「コンテナレジストリ」が出てくるので選択します。 すると作成したコンテナレジストリの一覧を表示するページが出てくるので、イメージがあることを確認します。
そして、設定にある「アクセスキー」を選択して「ログインサーバー名・ユーザー名・パスワード(いずれか)」の情報を確認しておきます。この情報はプール作成時に必要になるので、メモ等で控えておきましょう。

バッチアカウントの作成
さて、コンテナレジストリが使える事を確認できたので、次はバッチ側の準備を進めていきます。
Azureポータルの検索窓から「Batch」と入力してください。すると下の図のように「バッチアカウント」が表示されるので、選択してください。
すると作成したバッチアカウントの一覧が表示される画面が出てくるので、左上の「作成」を押します。
「新しいバッチアカウント」という画面が出てくるので、記入していきます。「アカウント名」は一意&どんなジョブを紐づいているのか分かるように命名します。場所は、Japan East かJapan Westを選択します。(もちろんそれ以外を選択しても良いのですが、選択した地域によっては使えない設定があったり、その国の法律が適用されるので、あらかじめどの地域を選択すべきかチェックしておくと良いでしょう。)
設定ができれば「確認と作成」を押してバッチアカウントができるのを待ちます。

プールの作成
次はプールを作成していきます。左側の機能から「プール」を選択します。

すると「プールの追加」という画面が出てくるので、必要事項を記入していきます。
ここでは
- プールの詳細
- オペレーティング システム
- グラフィックスとレンダリングのライセンス
- ノード サイズ
- スケーリング
などを設定していきます。
プールの詳細
ここではプールの名前を設定します。このプールにジョブを紐づけることになるので、どのようなプールなのかわかるように命名しておくと良いでしょう。
オペレーティング システム
ここではノードのスペックを決めます。
コンテナを動かすことができるノードの種類は決まっているので公式ガイドに沿って設定していきます。
・発行者「microsoft-azure-batch」
・オファー「ubuntu-server-container」(※ここはどのオファーを選択しても大丈夫です。)
・SKU「20-4-lts」(※オファーに紐づくSKUを選択してください。)

ここからは「コンテナ構成」を「カスタム」にすると出てくる項目を埋めていきます。
まずはコンテナイメージを設定します。バッチで実行させたい、コンテナレジストリにあるコンテナイメージを指定します。
次にコンテナレジストリの接続情報を設定します。前章「コンテナレジストリとイメージの準備」の最後に確認したコンテナレジストリのアクセス情報を下の画像のように入力していきます。

こちらの設定が出来なければイメージのPullに失敗するので、誤りがないか注意しましょう!!

ノード サイズとスケーリング
ここではジョブを実行するためのプール内のノードの設定を記述します。
VMサイズではノードの種類を選択します。CPU、メモリサイズ、GPUの有無など多種多様なVMを選択できるので最適なものを選ぶと良いでしょう。
スケーリングでは、「プールを常に起動し続けるのか?それとも必要に応じてスケールイン・スケールアウトできるように設定しておくのか?」等を設定します。今回は動作確認だけ行いたいので「固定モード」で「ターゲットの専用ノード数を1」に指定しました。業務で使う場合は、こちらも自分の要件に合った設定にしてください。

※低優先度ノードとは?
docs.microsoft.com
これで一通りの設定ができたので「OK」を押してプールができるまで5分~10分ほど待ちます。
プールを選択した時に、ヒートマップが下図のようなグレー状態であれば作成成功です。

ジョブとタスクの作成
あと少しでジョブの作成が完了します!プール選択した際に出ていた「ジョブの追加」を選択します。このジョブがどのような処理のまとまりをしているかわかるように命名しましょう。
なお、詳細設定を「カスタム」に変更するとジョブの実行に関する設定を指定できます。実務でAzure Batchを利用する場合は必ず設定するようにしましょう。今回はお試しなのでスキップします。

命名できれば「OK」を押します。すると「タスク」という画面が出てくるので、「追加」ボタンを押します。表示される「タスクの追加」では実行させる処理を記述していきます。
このページは「基本情報」と「詳細情報」の2セクションを埋めます。
まずは基本情報。タスクIDは他と被らないように命名する必要があります。コマンドラインはノード上のアプリケーションやスクリプトを実行する命令文を記述しますが今回は必要ないのでスキップします。

次は詳細設定。ここはタスク実行時の設定を行います。コンテナを実行させるので、必ずイメージの指定を行います。今回はプール作成時にリポジトリやイメージ名を既に指定しているので、そのイメージ名を指定します。プール作成時に指定していない場合はここでレジストリとイメージ名を設定します。

いざ動かしてみる!
タスクを作成すると自動的にタスクが開始します。タスクをクリックすると下の図のような画面が出てきます。ここでは「stderr.txt」と「stdout.txt」という2つのファイルがあります。
「stderr.txt」はerrとついている通り、タスク実行時に出力されるエラー文が記録されていきます。うまく実行できない場合はこちらを確認しましょう。
「stdout.txt」はタスク実行時に出力されるログが記録されていきます。正常に実行されているかの指標となるので、書き込まれているか確認しましょう。
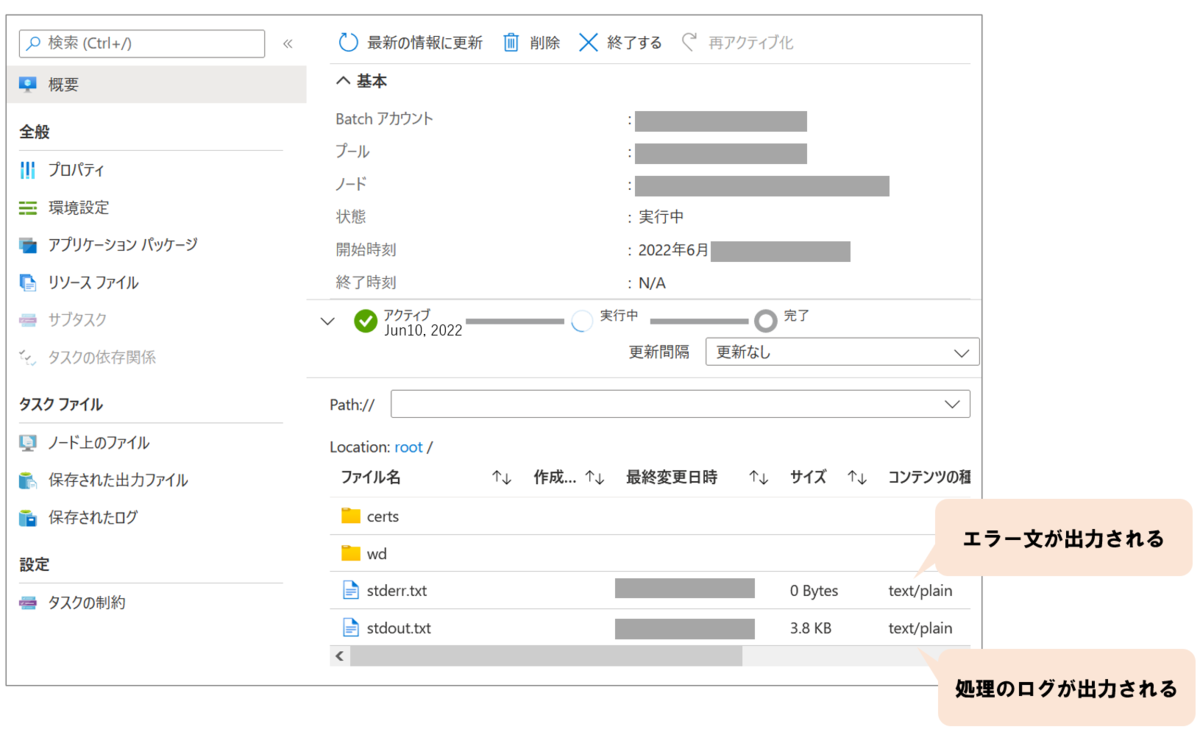
「状態」が「完了」になっていれば完了です!
おまけ:コスト削減したい!
「VMをたくさん使いたいけど、使用時間に応じて費用が上がっていく仕組みなので使うの迷うな....でもXXXXX使いたくないな・・・」といった場合、作成したプールごとにスケーリングを設定することが可能です。
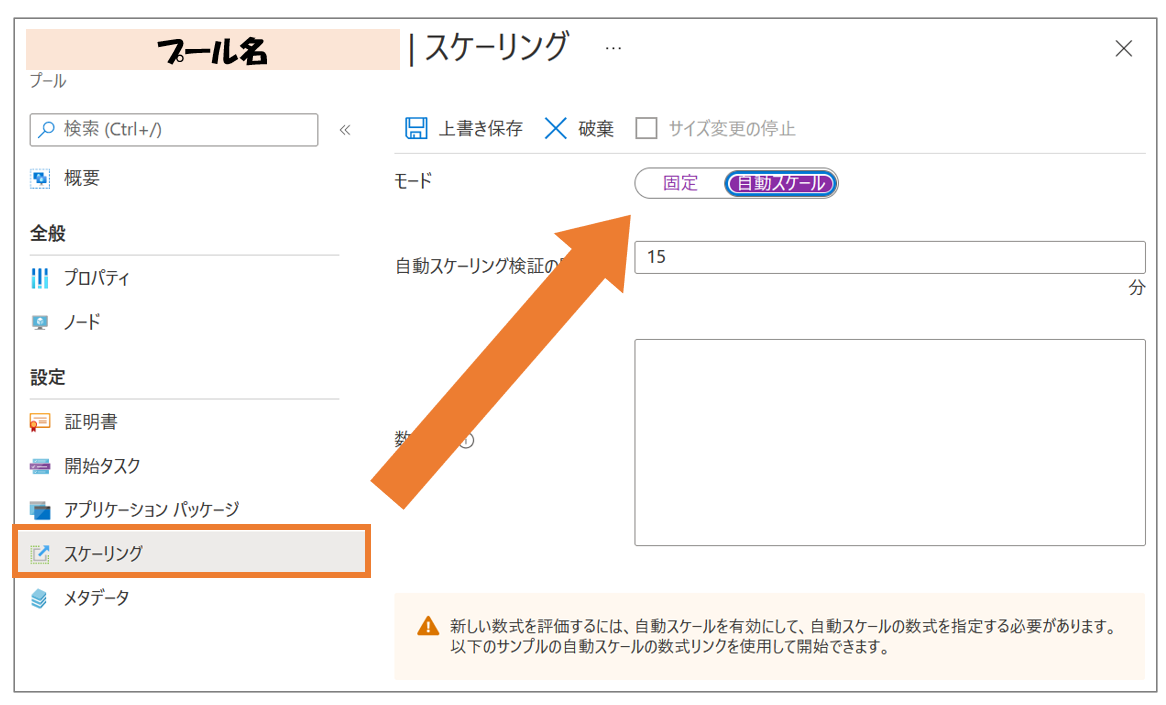
公式のリファレンスに設定できる値などが書いているので、こちらを参考にしてみてください。
