株式会社神戸デジタル・ラボ DataIntelligenceチームの高木です。
今回は、ドラッグ&ドロップで視覚的に機械学習モデルの訓練とデプロイができるMicrosoft社がAzure上で提供するAzure Machine Learning デザイナー(以降、Azureデザイナー)について取り上げます。
尚、本記事は同様にAzure上で提供されているAutomated Machine Learning(以降、AutoML)を取り上げたこちらの記事と同じデータを取り扱っており、本記事中でも何度かこちらの記事に言及することもありますので、まだ読まれていない方は是非こちらの記事もご一読ください。
Azure Machine Learning デザイナーとは?
冒頭に紹介したAuto MLの記事では、画面に表示される選択肢を選ぶだけで機械学習モデルの作成をノーコードで実現できるMicrosoft社のサービスを紹介しました。今回は、ドラッグ&ドロップ操作といった視覚的な操作のみでモデル構築が実現できる同社サービスをご紹介いたします。Azureデザイナーでは、データの読み取りから機械学習モデルの作成までの一連の流れをコンポーネント(ある特定の機能を持つプログラム部品)を組み合わせて実装していきます。Azureデザイナーを利用することで、モデルの作成者以外でもどのようなフローで処理がおこなわれているかを視覚的に理解することができます。
環境を作成し、データを準備しよう
環境を作成する
Azureデザイナーは、Azure Machine Learningのサービスの一部であるAzure Machine Learning Studioから利用することができます。Azure Machine Learningを利用する際にワークスペースを作成する必要があります。しかし、初めてAzureを利用する方にとってワークスペースを作成するのは難易度が高いです。ワークスペースの作成経験がない方は、過去に詳細な解説記事を公開しているので、こちらの記事の「Step2)ワークスペースを新規作成する」までの手順を参考にしながら準備をしてください。
データを準備する
今回はAutoMLの記事と同じirisデータと呼ばれデータセットを利用します。このデータセットには、アヤメという花についての情報が格納されています。
このデータセットは、各アヤメに関する4つの測定値と品種名の計5つの情報がテーブル形式で構成されています。アヤメの品種名はvarietyという列名になっており、具体的な値はSetosa・Versicolor・Verginicaの3種類です。
品種名以外の4つの測定値は、花びらとがくの長さと幅に関しての情報です。
| 列名 | 単位 | 詳細 |
| sepal.length | cm | がく片の長さ |
| sepal.width | cm | がく片の幅 |
| petal.length | cm | 花びらの長さ |
| petal.width | cm | 花びらの幅 |
データセットの登録方法は、AutoMLの記事の「データをアップロード」のチャプターで説明しています。手順を参考にしながらご準備ください。
機械学習の一連の流れを理解しよう
Azureデザイナーの実装に入る前に、今回行う機械学習モデルの作成の一連の流れを見ておきましょう。
(1) データに対して前処理を行う 機械学習において生データをそのまま利用せずに、前処理と呼ばれるデータの性質を最大限に活かせるようにするための作業はよく行われます。今回の実装では、数多くの前処理方法の中から正規化(データを一定のルールに基づいて変形する)と呼ばれる方法を採用します。
(2) 訓練データと検証データに分割する 訓練データと検証データの割合を指定して分割するホールドアウト法を用いることによって、一つのデータテーブルからでも効率よくデータを得ることができます。今回は訓練データと検証データの分割を7:3と指定して、ホールドアウト法で分割を行います。
データの分割によってどのような効果があるのかを更に詳しく知りたい方は、こちらの記事の「ホールドアウト検証とは」を参照してください。
(3) 訓練データでモデルを学習させる メイン部分のモデルの学習は機械学習のアルゴリズムの中で最もシンプルな線形回帰を用いて実現します。他にもポアソン回帰など多くのモデルが利用可能なので、線形回帰と他モデルでの結果比較などを行ってみても面白いですね。
(4) 検証データでモデルを評価する 「訓練データでモデルを学習させる」で作成したモデルの精度を評価するために、検証用データを読み込ませて結果を確認します。
いざ、実装!
それでは、上記の流れを実際にAzureデザイナーで実行してみましょう。左タブの中からデザイナーをクリックし、プラスボタンを選択することで実装画面に移ることができます。

実装画面では、下図の赤枠で囲われているコンポーネントを画面右側のキャンバスにドラッグ & ドロップ してデータやコンポーネントを配置していきます。まず、最初に今回利用するiris datasetを登録しましょう。

赤枠で囲われたデータのコンポーネントを右画面に移動させることで、キャンバス上に選択したコンポーネントが追加されます。
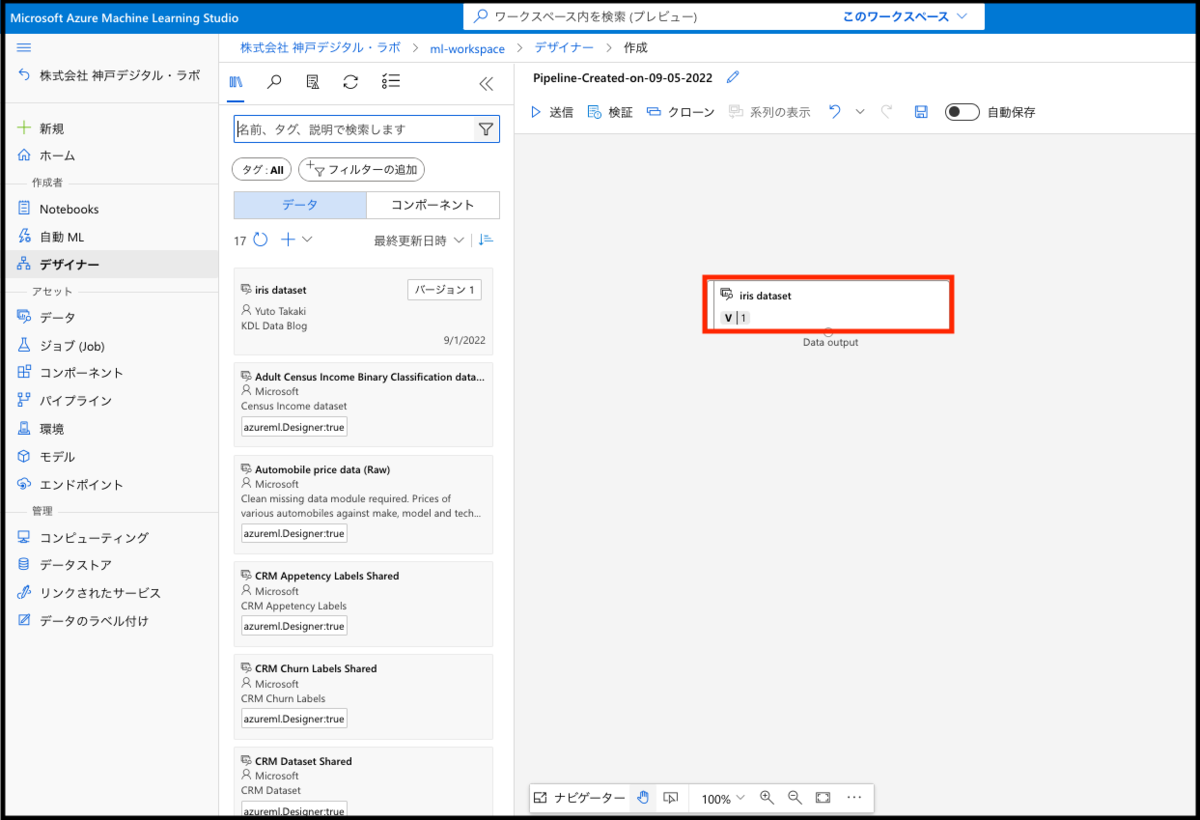
データセットの準備はたったこれだけです。とても簡単ですね。次は、先程示した機械学習モデルの作成の一連の流れに沿って進めていきます。
データに対して前処理を行う
データに対する正規化の前処理の役割を果たすNormalize Dataをキャンバス上に追加します。
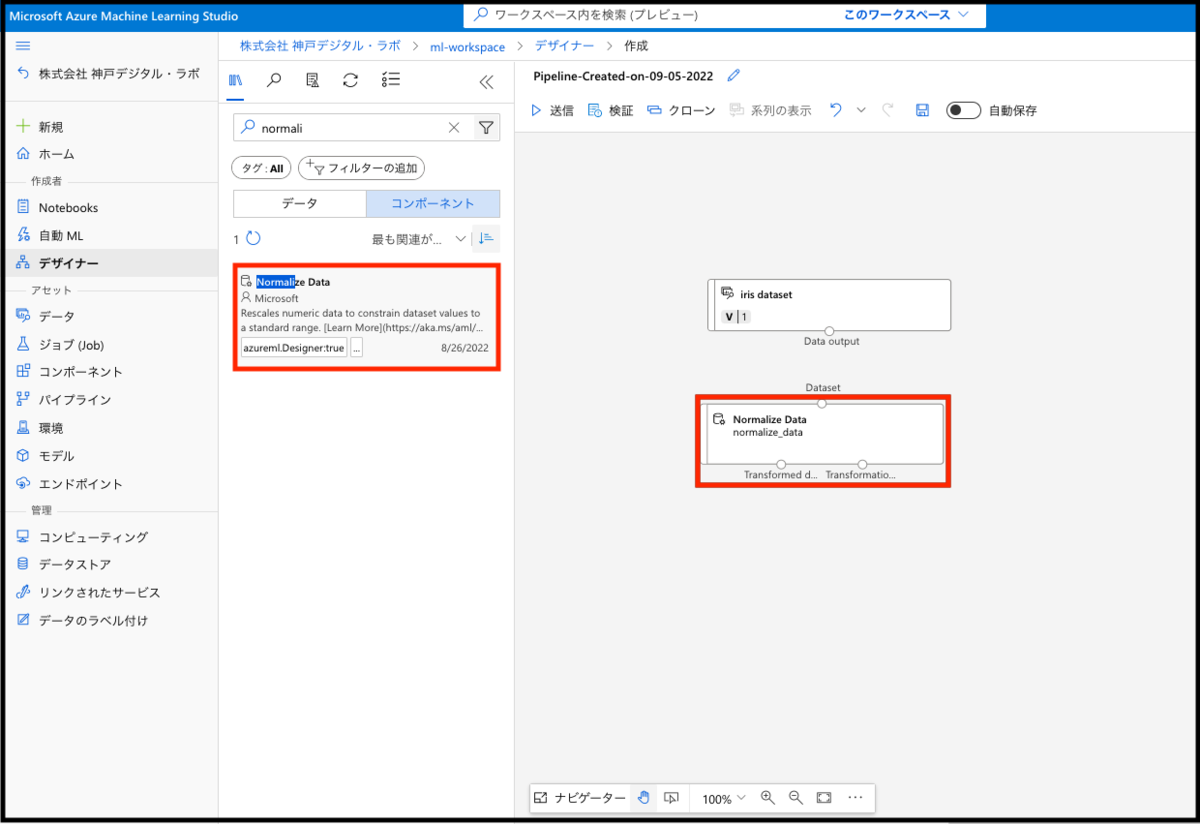
コンポーネントをキャンバスに用意した後は、各コンポーネントを繋ぎ合わせる作業が必要になります。こちらは、各コンポーネントの点同士をクリックして実現します。コンポーネントを繋ぎ合わせる事で処理の順番を指示しているイメージです。この処理を行うことで、Azureデザイナーだけではなく、人間にとってもどのような処理が行われるのか視覚的に捉えることができますね!

コンポーネントは細かい項目を設定することも可能です。ダブルクリックすることで、右側に複数の選択項目が出てきます。今回は、Columns to transformの項目で「どの列に対して正規化を行うのか」を指定していきましょう。標準化方法は、デフォルトのzスコア(各データに対して平均値を引いて、標準偏差で割る)を用いるので、特にデフォルト値からの変更は不要です。
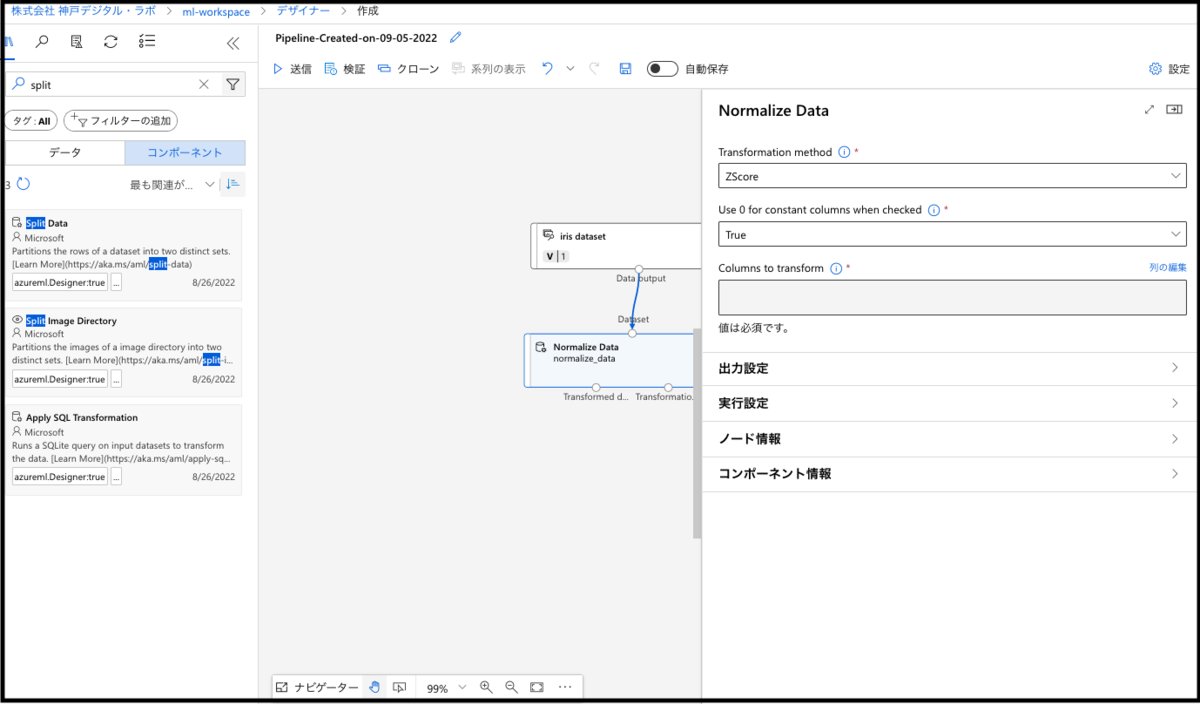
Normalize Data の入力にデータセットを指定することで、下図のように視覚的かつ簡単に列を選択することができます。今回は、ラベル列(モデルが予測したい項目)となるvariety以外の列を全て選択します。

【要注意】
本来は上記のように名前選択によって列名を指定することが可能ですが、今回は列名に「.(ドット)」が入っていることが原因なのか列名を指定するとエラーが出ることが確認されています。よって、下図のように各列の列番号を指定することで対応してください。

訓練データと検証データに分割する
Split Data を利用することでデータを分割できます。
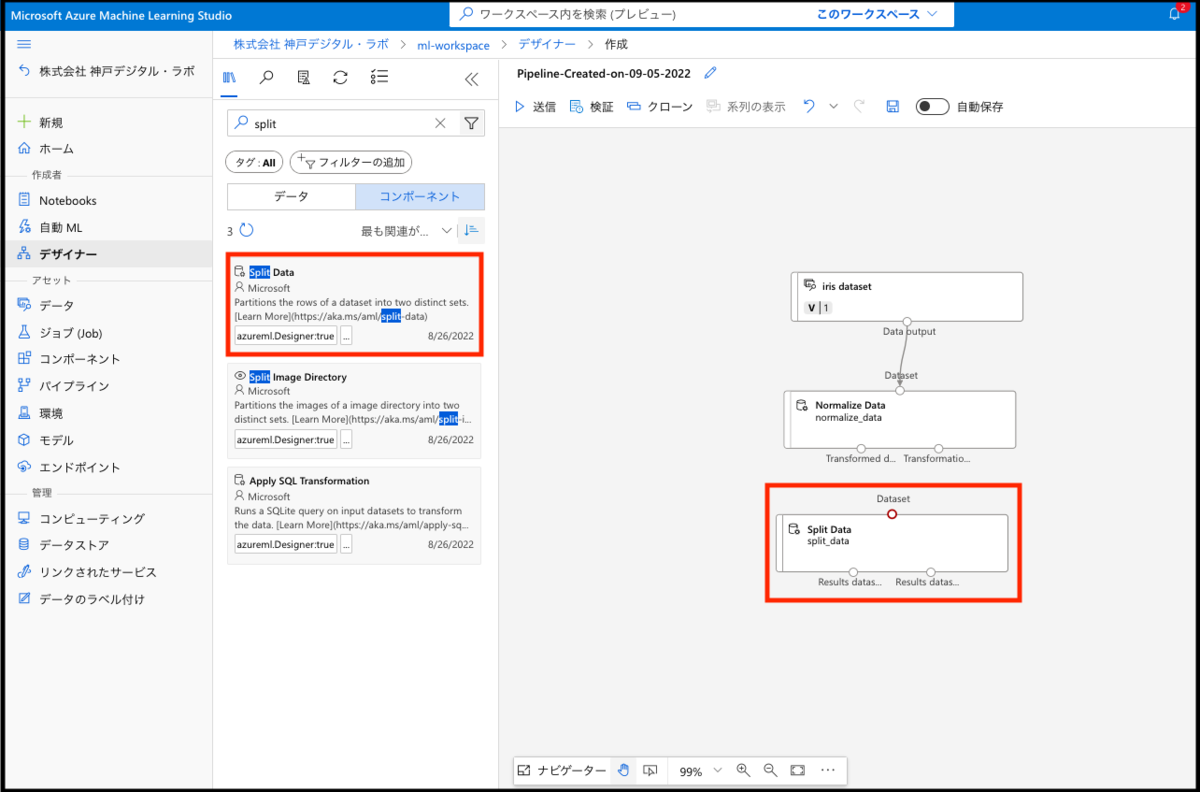
こちらも、前段の Normalize Data と繋ぎ合わせるのですが出力の左側のポイントと繋げることに注意してください。左側のポイントはTransformed dataset、右側のポイントはTransformation functionという名前です。この名前を参照すると分かる通り、前処理をしたデータを出力しているのは左側です。ですので、Split Data の入力には、コンポーネントの左側の出力を利用します。(Transformation functionは、今回の正規化方法を異なるデータセットに対しても同様に行いたい時に用います。)

Split Data にも詳細設定をしていきましょう。今回は、以下のように設定してください。
【Splitting mode】Split Rows 【Fraction of rows in the first output dataset】0.7 【Randomized split】True 【Random seed】42 【Stratified split】False

こちらの設定では、訓練データと検証データの割合を7:3に設定し、行をランダムにシャッフルすることでデータに散らばりを持たせています。(ランダムにシャッフルする際にはシード値を決定しておくと再現性を保つことができるので、今回は42という値を設定しています)
訓練データでモデルを学習させる
今回のモデルの学習では線形回帰を利用します。Azureデザイナーでは、線形回帰を示す Linear Regression コンポーネントとモデルの訓練を実際に行う Train Model コンポーネントの二つを使用します。

続いて繋ぎ合わせる部分ですが、Linear Regression は Train Model の入力の左側のUntrained modelに、Split Data の左側の出力であるResult dataset1を Train Model の入力の右側のDatasetに繋げてあげましょう。これによりTrain Modelがどのデータを、どのアルゴリズムで処理するかという指示が完成します。
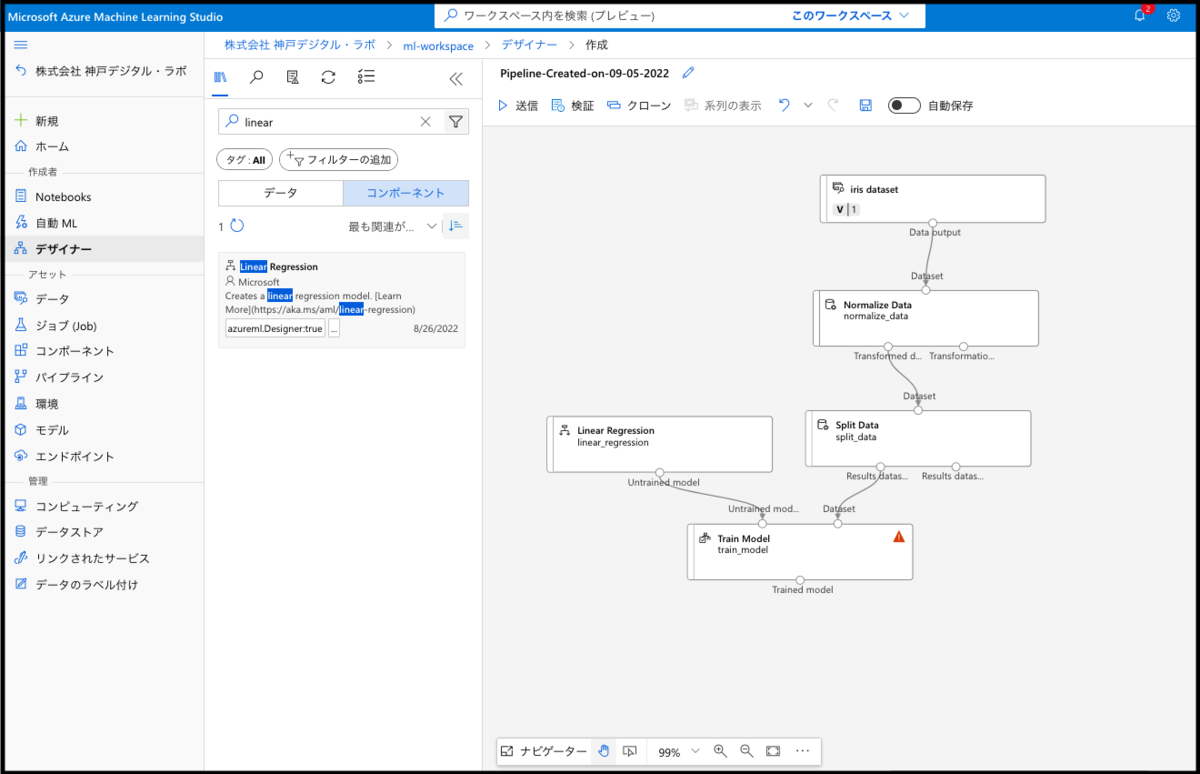
Train Model コンポーネントではどの列をモデルの予想にするのかを指定する必要があります。

Label columnの列に、アヤメの品種を示すvarietyを入れてあげましょう。 注)こちらは、列名に「.(ドット)」が入っていないので列名の指定を利用しましたが、先程同様各列の列番号を指定してももちろん構いません。
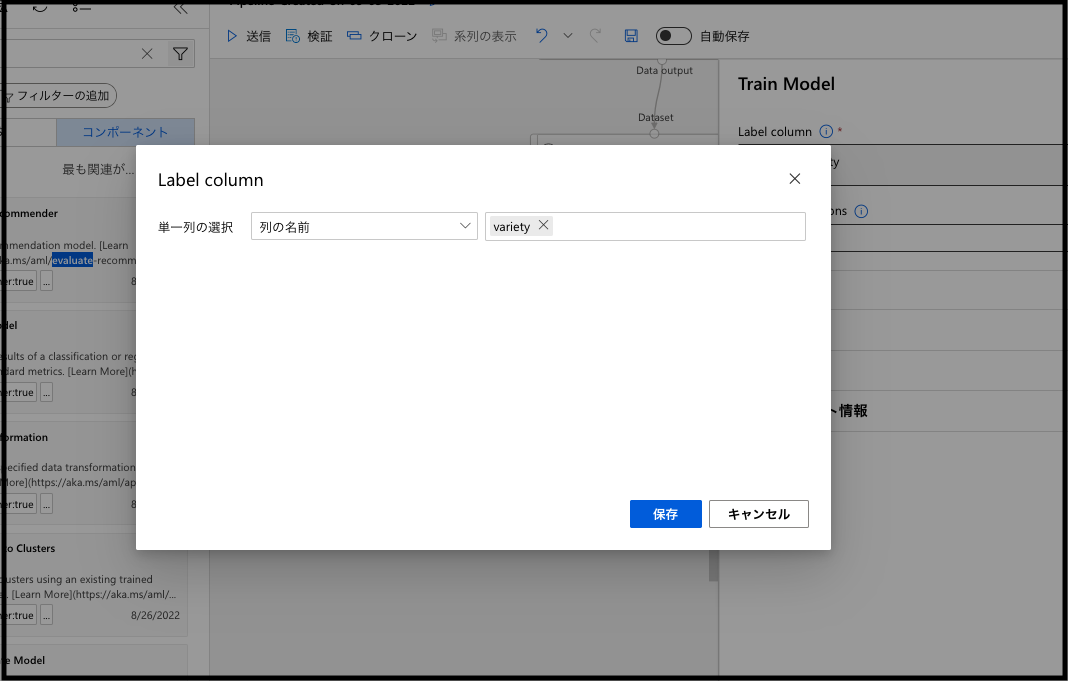
検証データでモデルを評価する
最後に訓練したモデルがどれくらいの精度となるのかを評価します。こちらでは、検証データを実際にモデルに入力して出力を得る Score Model と評価値を算出する Evaluate Model の二つのコンポーネントを使用します。
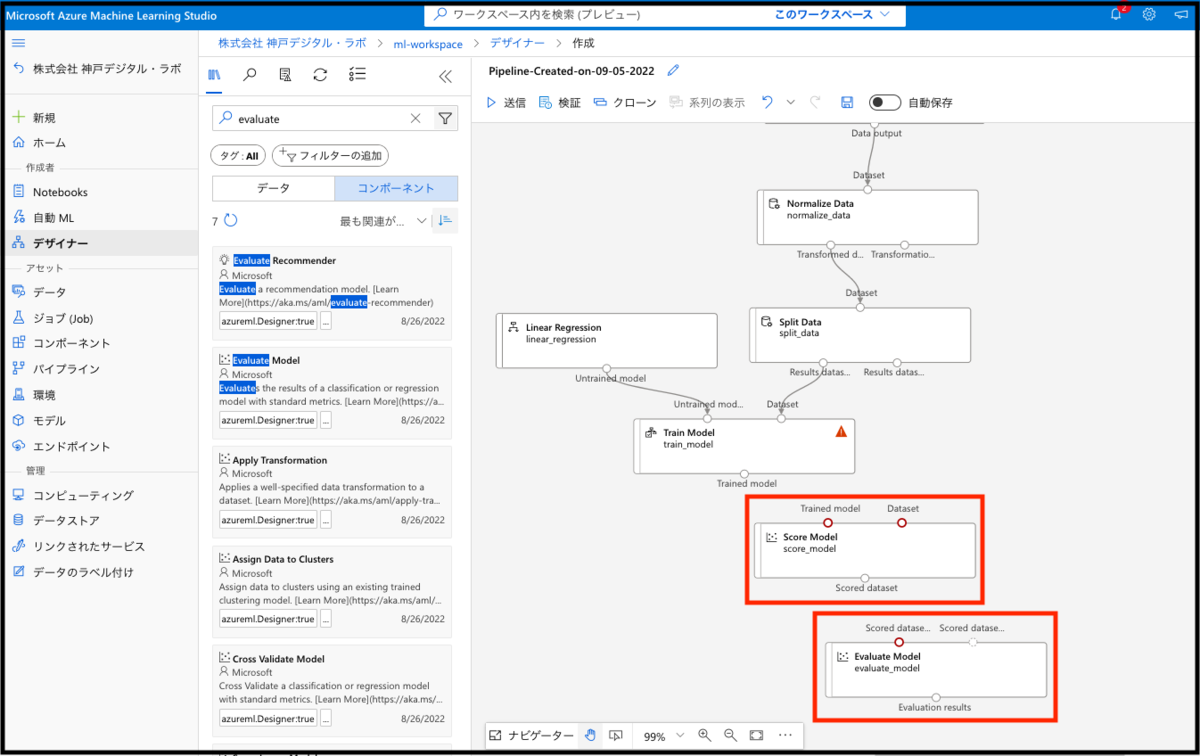
こちらの繋ぎ合わせですが、Train Model の出力を Score Model の入力の左側に、Split Data の出力の右側のResult dataset2を Score Model の入力の右側に繋ぎ、Score Model の出力を Evaluate Model の入力の左側に繋ぎ合わせます。

配置を整える
以上で全コンポーネントの配置が完了しました。コードを書くことなく、コンポーネントをドラッグ & ドロップするだけでモデルの一連の実装(データの前処理からモデル作成・評価まで)が完了してしまいましたね。最後に、コンポーネント間の配置を微調整しておきましょう。下部にあるナビゲータ画面の一番右の三点マークをクリックすると、自動レイアウトという項目が表示されます。こちらをクリックすると、コンポーネントの配置を自動に整形してくれます。

調整した後がこちらです。

適用前と比較して、綺麗に整えられていますね。
モデルを実行(送信)しよう
定義したモデルを実行するためには、どのインスタンス(仮想マシン)で実行するか設定が必要です。こちらは、画面右上の設定ボタンを押すことでインスタンスを選択できます。
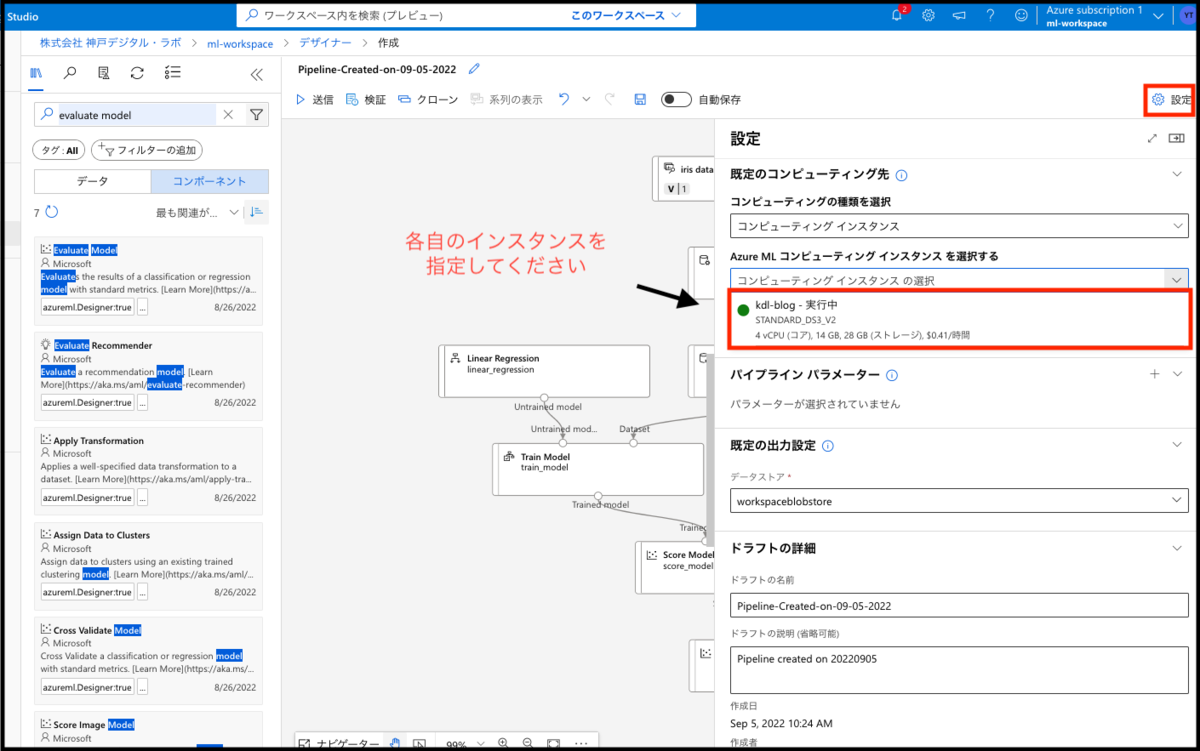
「AzureMLコンピューテングインスタンスを選択する」の選択項目に、各々のインスタンスを選択してください。設定が終わり次第、画面上部にある送信ボタンを押してください。

すると、下図のような画面が現れます。こちらで実験名を入力して、送信することで実際にプログラムが動き始めます。

実行完了にはしばらく時間を要しますので、優雅にコーヒーでも飲みながら待つことにしましょう。
結果を確認しよう
しばらく待って左タブにあるジョブの一覧を見てみると、先程実行した実験が確認できます。

さらに実験名をクリックすると、次はパイプライン名が表示されます。(パイプラインは、Azureデザイナーでの実行内容・結果を示します。)実は、一つの実験名に対してパイプラインを複数対応づけることができるのですが、今回は一度しか実行(送信)していないのでパイプラインは一つだけの表示になります。
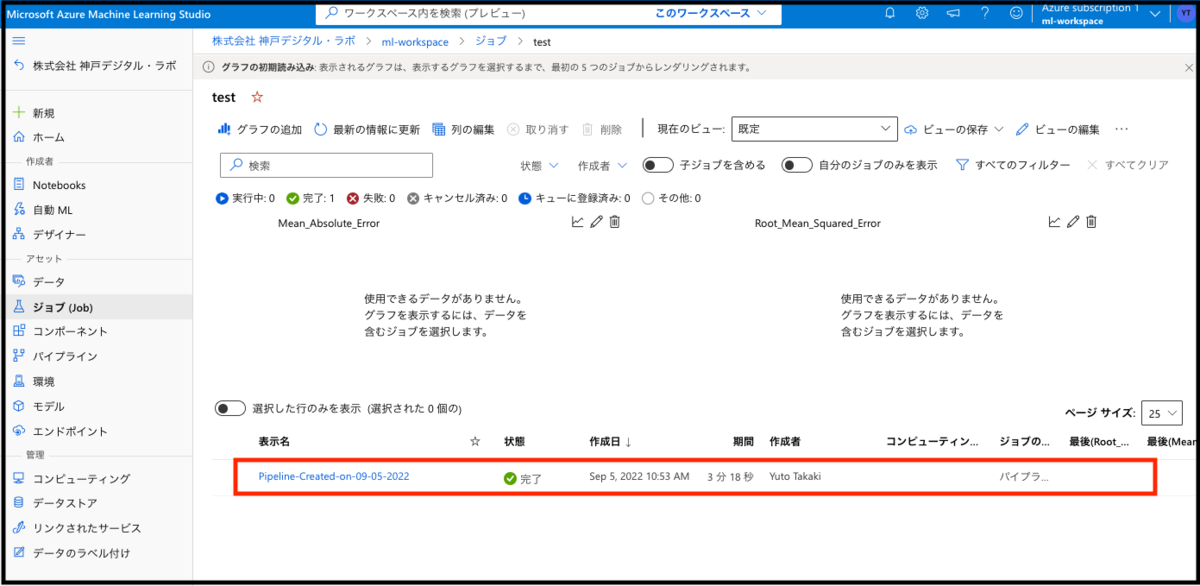
表示されたパイプライン名をクリックすると、下図のような画面が表示されます。赤枠で囲われているコンポーネントEvaluate Modelをダブルクリックしてください。

すると、右側にいくつか数値がでてきました。今回はこの中の、Coefficient_of_Determination に注目します。
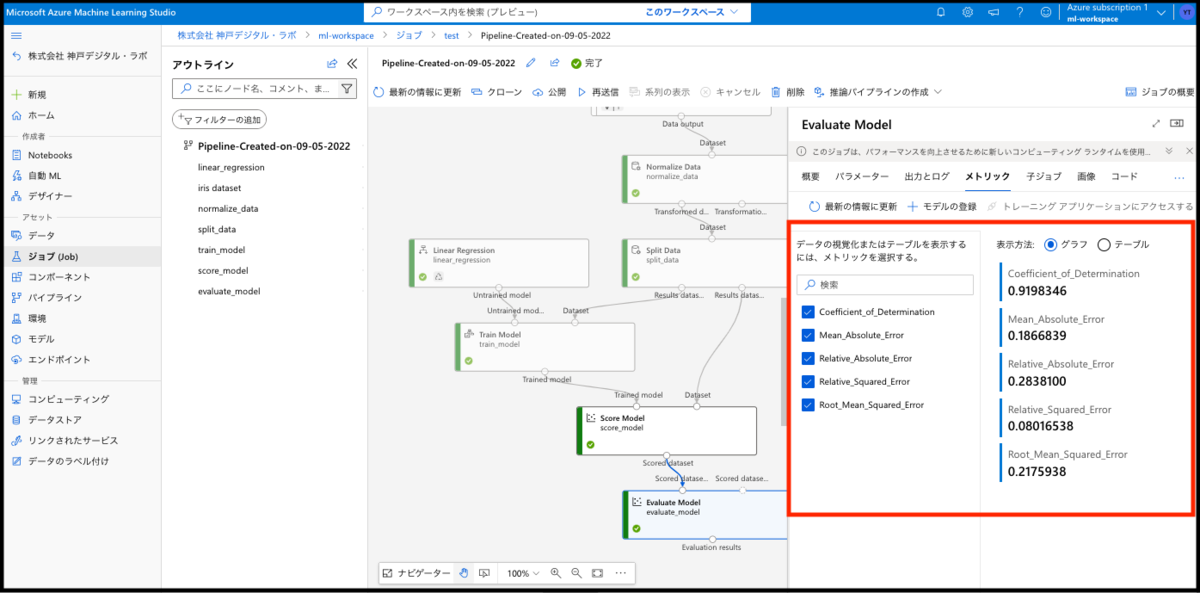
Coefficient_of_Determination は日本語に訳すと決定係数という意味です。決定係数とは、「通常 0〜1.0 の範囲でモデルがどれほどデータに寄り添えているか」を示す値であり、値が大きいほどモデルがデータに寄り添えている(当てはまりが良い)となり、良いモデルと言えます。今回、こちらの値が0.9198346ということでかなり良い結果といえるでしょう。コードを一行も書くことなく、これほどの精度が出るなんて驚きです!
まとめ
今回はAzureデザイナーを利用した実装について扱いました。GUI上の操作のみなのでコードを書くことなく、コンポーネント間の関係性を利用してモデルのフローがわかりやすいことが特徴ですが、それだけではなく高いモデルの精度を出すことができることが確認できましたね。Azureデザイナーは、前回扱ったAutoMLと比べると専門的な知識が必要ですが、どのようなフローでモデルが構築されたかを視覚的に把握できます。そのため、作成者以外の人にも共有しやすく、コンポーネントの関係性を簡単に操作できるためとても優れたツールだと感じました。皆さんもお手元のデータで、ぜひ一度お確かめください。

データインテリジェンスチーム所属
データサイエンティスト。自然言語処理を中心としながら、その他の非構造化データや構造化データに関しても偏りなく扱います。こちらのブログでは、自然言語処理に関するトピックやAzureを中心としたクラウドを利用したデータ活用に関してのトピックを中心に様々な記事を発信していきます。
