株式会社神戸デジタル・ラボ DataIntelligenceチームの高木です。
今回は、画面上の操作だけで機械学習モデルを作成できるMicrosoft Azure(以下、Azure)のAutomated Machine Learning(以下、AutoML)について取り上げます。
AutoMLとは?
近年機械学習は普及し、データ活用においての有効性は多くの方に認知されています。その一方で、実際に機械学習モデル(データを入力すると予測を返してくれる機構)を自ら構築するには、知識や技術面で高いハードルが存在します。この問題を解決するツールが、Microsoft社が提供するクラウドサービスAzure上で展開されているAutoMLです。AutoMLを利用することにより、画面に表示される選択肢を選ぶだけで機械学習モデルを作成できます。以降のチャプターから、一緒に体験しましょう!!
AutoMLを利用できる環境を作成しよう
AutoMLは、Azure Machine Learningのサービスの一部であるAzure Machine Learning Studioから利用することができます。このことから、Azure Machine Learningを利用する際に必須のワークスペースを作成しなければなりません。こちらは初めてAzureに触れる方には少し難解です。ワークスペースの作成経験がない方は、過去に詳細な解説記事を執筆しているので、こちらの記事の「Step2)ワークスペースを新規作成する」までの手順を参考にしながら準備をしてください。
本記事ではワークスペースは作成済みのものとし、Azure Machine Learning Studioのホーム画面から順にご紹介していきます。
データを確認しよう
今回は、モデルの構築のためにirisデータと呼ばれるデータセットを利用します。こちらは、機械学習のチュートリアルでよく使われているデータサイエンティストには馴染み深いデータセットです。
気になるデータの詳細ですが、アヤメという花についての情報が格納されています。具体的には、各アヤメに関する4つの測定値と品種名の計5つの情報がテーブル形式になっています。アヤメの品種名はvarietyという列名になっており、具体的な値はSetosa・Versicolor・Verginicaの3種類です。
品種名以外の4つの測定値の詳細はこちらです。花びらとがくの長さと幅に関しての情報になっています。
| 列名 | 単位 | 詳細 |
| sepal.length | cm | がく片の長さ |
| sepal.width | cm | がく片の幅 |
| petal.length | cm | 花びらの長さ |
| petal.width | cm | 花びらの幅 |
データをアップロード
実際にモデルを作成する前に、Azure Machine Learning上に今回利用するirisデータをアップロードしましょう。
まず、ホーム画面の左にあるサイドバーから【データ】をクリックしてください。
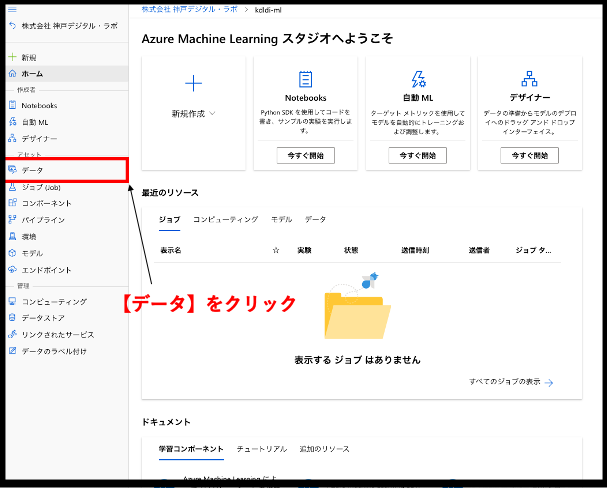
下図のような画面が表示されたと思います。こちらにAzure Machine Learningで利用するデータを保存することができます。画面上の【作成】ボタンから【Webファイルから】を選択してください。
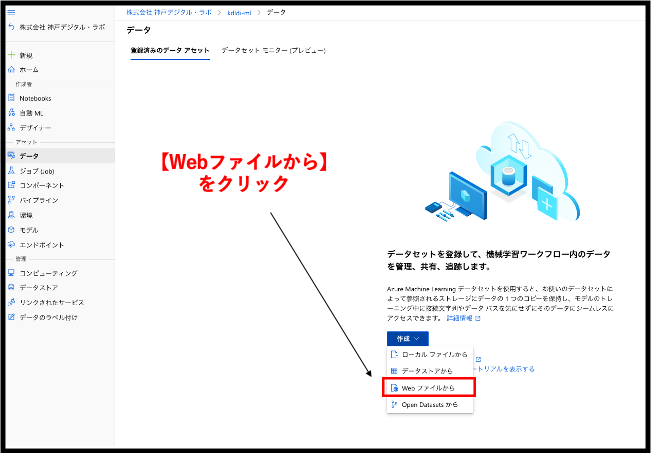
データの基本情報を入力する画面に遷移しました。先ほどのirisデータのURLをこちらに入力して、データセットの名前を入力してください。今回は、iris datasetとしておきます。データセットの種類は、今回はテーブルデータなので表形式を選択します。データの説明は、後から自身でデータの特徴が理解しやすいような記載をしておきましょう。入力が終わったら、次に移りましょう。 【WebURL】:https://gist.githubusercontent.com/netj/8836201/raw/6f9306ad21398ea43cba4f7d537619d0e07d5ae3/iris.csv 【名前】:iris dataset 【データセットの種類】:表形式 【説明】:KDL Data Blog
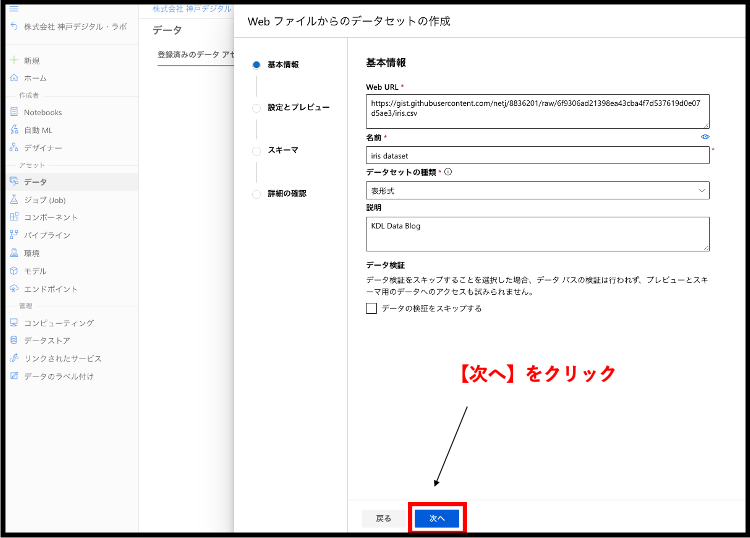
設定とプレビューの画面に切り替わりました。ここでは今回利用するファイルをどのようなルールで扱うかを設定します。今回は、どちらもデフォルトの値のままで以下のような設定になっています。入力が確認できたら、次へをクリックしましょう。 【ファイル形式】:区切り 【区切り記号】:コンマ 【エンコード】:UTF-8 【列見出し】:すべてのファイルで同じヘッダー 【行のスキップ】:なし
続いて、スキーマ(データの特徴についての情報)の画面が表示されました。ここでは、データのカラム(列)に関する情報を設定します。AutoMLではすべての情報を一から登録する必要がなく、「多分、この列に関するデータの特徴はこうなんじゃないの?」という予想を自動で行います。時々予想が外れていることもありますが、全てを自分で設定する必要がないのはすごく便利ですね!今回のデータにおいては自動で正確に予測してくれているので、特に変更する部分はありません。次にいきましょう!
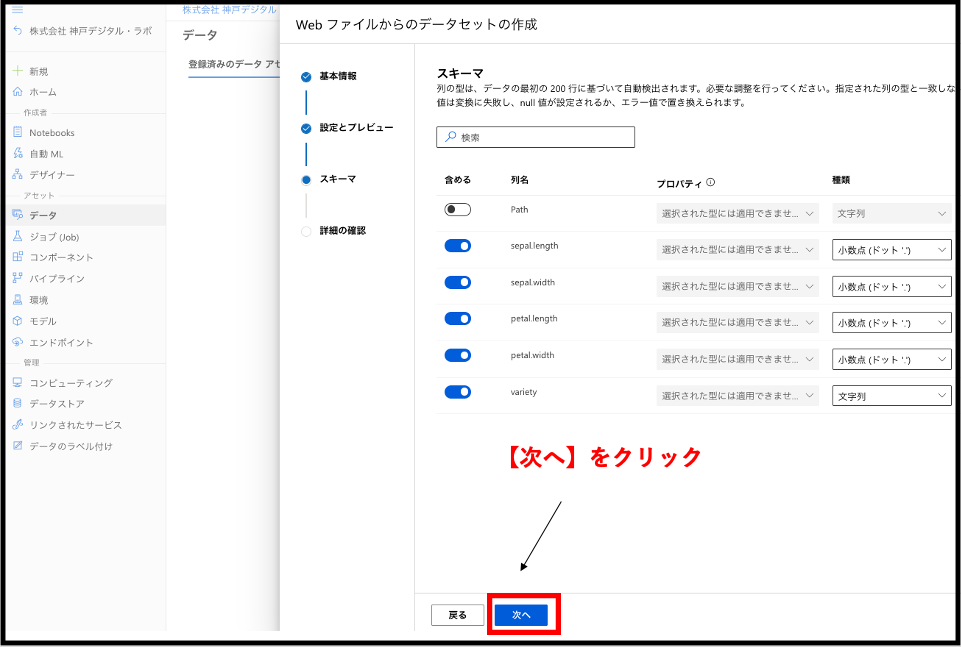
最後に詳細の確認です。下の画像と設定が同じであるかを確認してください。特に、問題がなければ【作成】を押してください。これで、Azure Machine Learning上にirisデータが作成されるはずです。
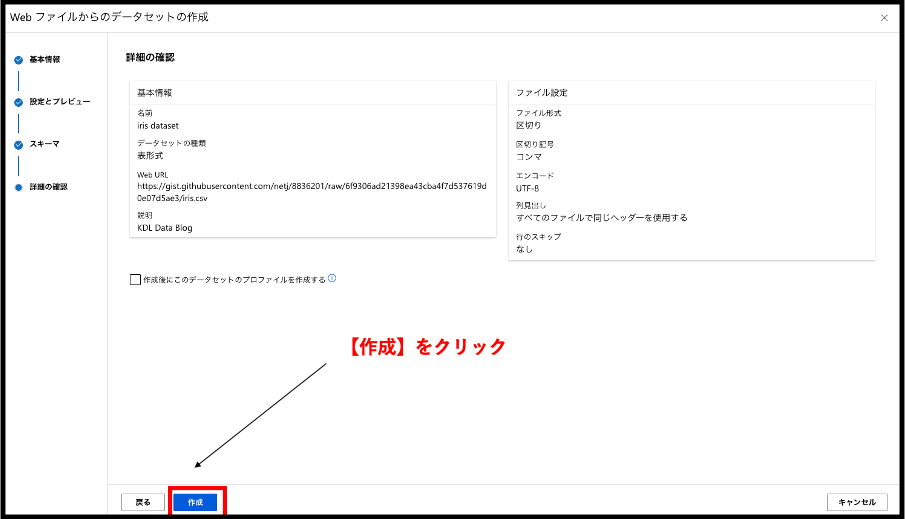
一番最初に登場したサイドバーにある【データ】をクリックしてみてください。すると、今回作成したデータセットが確認できます。
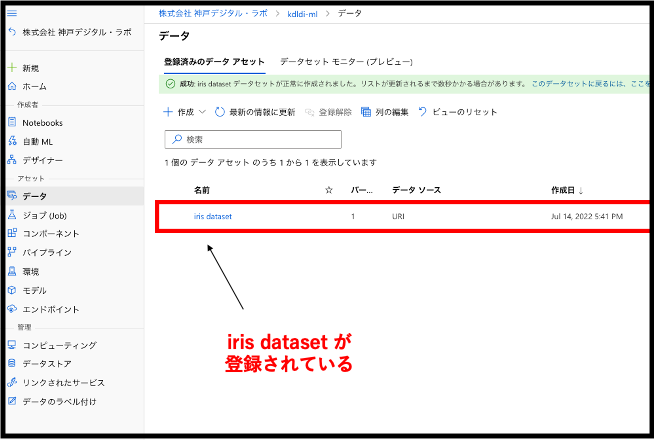
データのアップロードは以上で完了となります。続いては、AutoMLのメイン部分であるモデル構築の部分です!
実際にモデルを作成してみよう
今回は、アヤメの種類を4つの観測データ(花びらとがくの長さと幅)から品種を予測できる分類モデルを作成したいと思います。コーディングをすることなく、機械学習モデルが構築できるAutoMLの醍醐味を一緒に体験していきましょう!!!
まずは、ホーム画面の左にあるサイドバーから【自動ML】をクリックしてください。
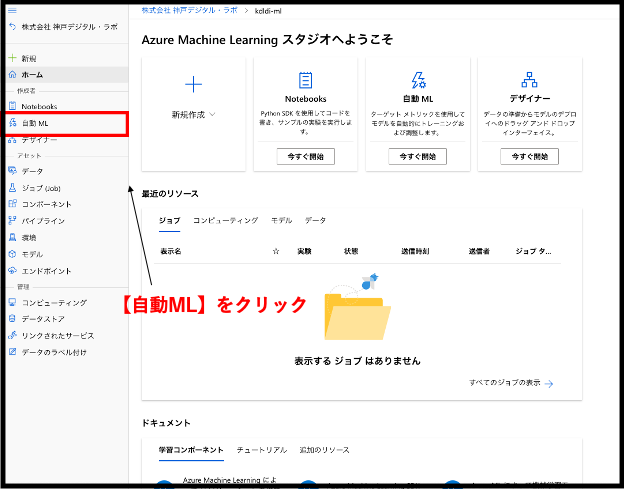
下図のような画面が表示されると思います。こちらが自動機械学習モデルを作成するスペースです。早速、画面左上にある【新規の自動機械学習ジョブ】のボタンをクリックし、実際にモデルを作っていくことにしましょう。
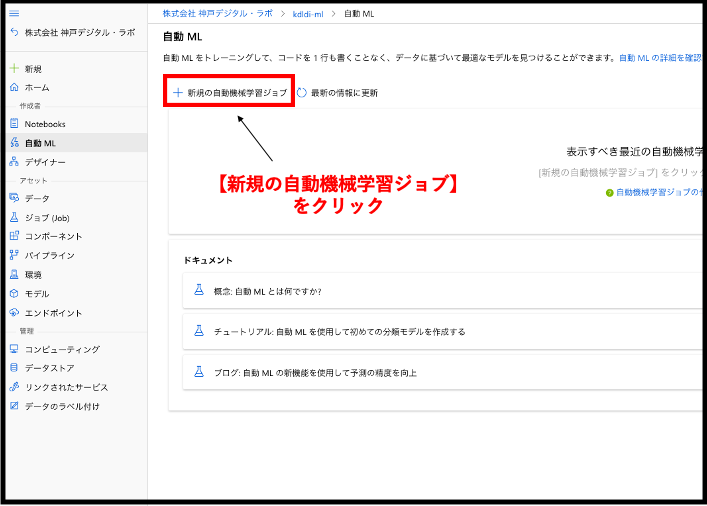
データセットの選択画面に遷移しました。先ほどのデータのアップロードに成功していれば、登録したデータセット名が表示されているはずです。登録したデータセットにチェックをつけて、【次へ】をクリックしましょう。
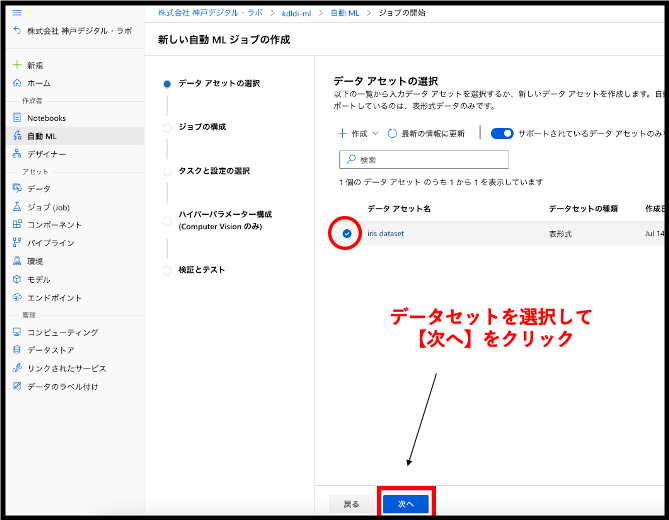
続いて、ジョブの構成画面に切り替わりました。実験名の項目から【新規作成】を選択してください。そして、任意の実験名を作成し、ターゲット列・今回利用するコンピューティングの種類と名称を入力します。ここでいう、ターゲット列というのはモデルが予測する列のことを指しており、今回ではvariety(アヤメの品種名の列名)がそれにあたります。続いて、【コンピューティングの種類を選択】の項目ですが、こちらはどの仮想マシンを利用するかを指定します。機械学習モデルを作成する上で、仮想マシンの構成やスペック(CPUやGPUなど)はとても重要な事項です。こちらでは、あらかじめ作成しておいたコンピューティングインスタンスを指定してください。すべての項目が入力できたら次へいきましょう!
【実験名】:新規作成 【新しい実験名】:classification 【ターゲット列】:variety(String) 【コンピューティングの種類を選択】:コンピューティング インスタンス 【Azure ML コンピューティング インスタンス を選択する】:ご自身の作成したインスタンスを選択してください
注)コンピューティングインスタンスを指定するには、状態を実行中にする必要があります。ホーム画面の左にあるサイドバーの【コンピューティング】をクリックし、ご自身のコンピューティングインスタンスの状態が「実行中」になっているかを確認してください。「停止中」になっている場合はコンピューティングインスタンスを選択し、上部にある開始ボタンをクリックすることで状態が「実行中」に変更します。また、ホーム画面の左にあるサイドバーの【コンピューティング】をクリックし、コンピューティングインスタンスが表示されない方は、まだ作成されていない可能性が高いので、先ほど紹介した記事を参照してみてください!
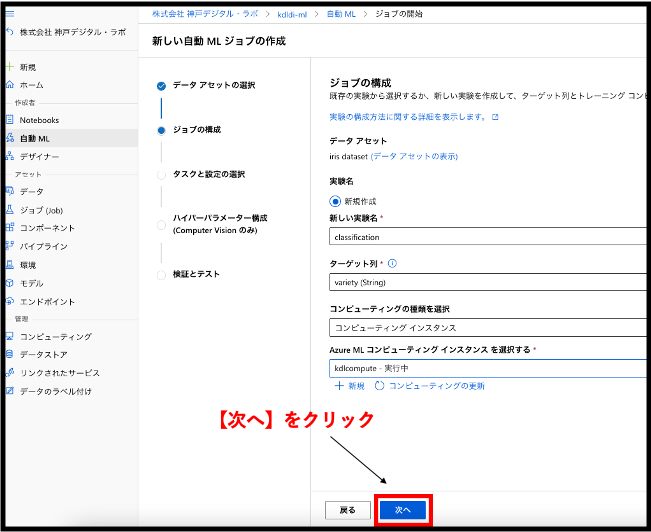
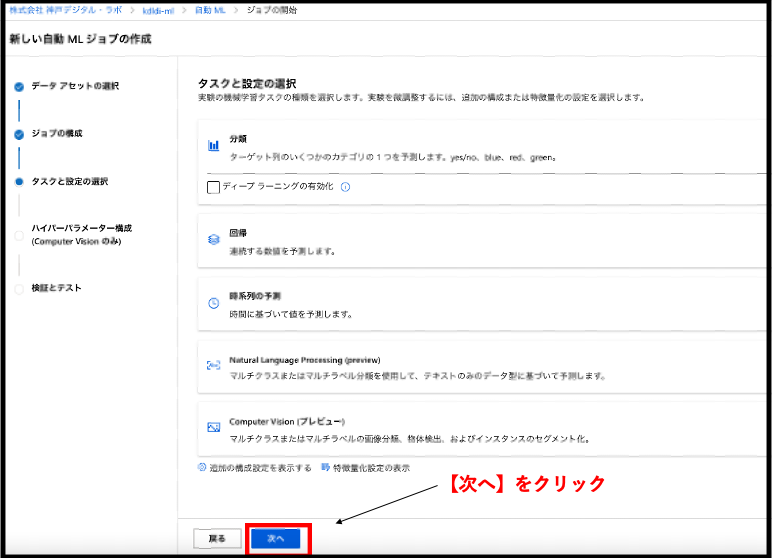
続いて、タスクと設定の選択です。今回は分類モデルを作成しますので、分類にチェックをつけてください。ここで学習に関する細かい設定を行います。【追加の構成設定を表示する】をクリックして右側に追加の構成が開くことを確認してください。
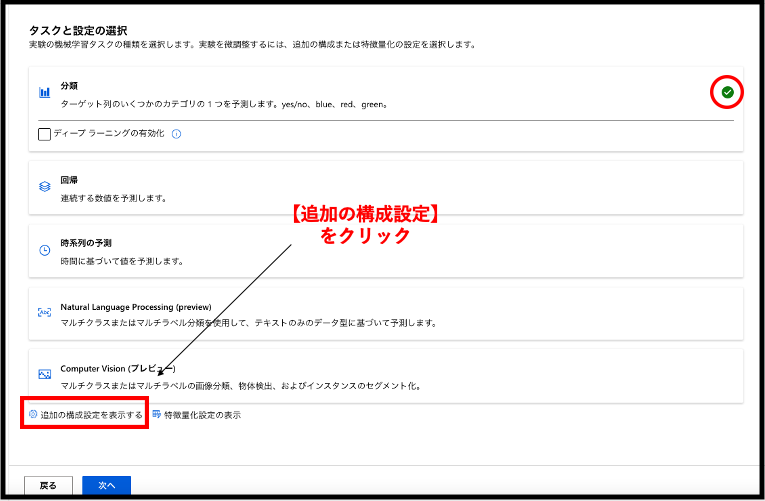
追加の構成は、以下の二つの項目に対して行います。
- 適用するアルゴリズムを限定する
- 学習時間の最大値を設定する
適用するアルゴリズムを限定する
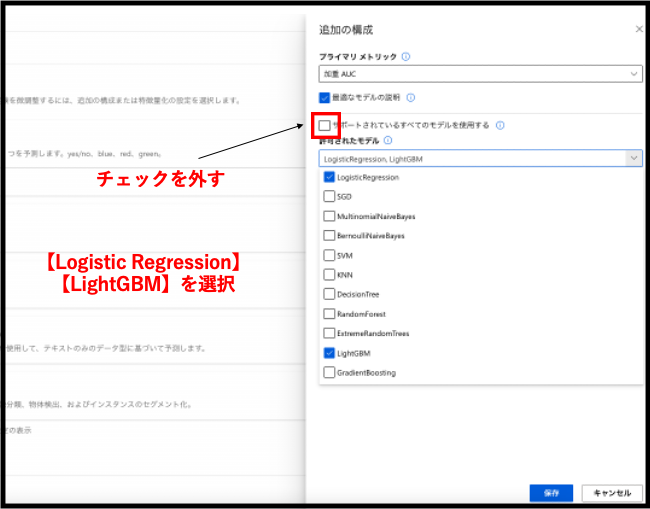
AutoMLのデフォルトの設定では、分類タスクの際に11種類のアルゴリズムが利用されます。機械学習は、一種類のアルゴリズムを実行する場合に対して多くの時間を要することから、実行時間を少しでも短縮する目的で、今回は11種類の中からLogisticRegressionとLightGBMの二種類のアルゴリズムを適用しようと思います。こちらを簡単に説明すると、LogisticRegressionは分類タスクを行う際に最もよく使われるアルゴリズムであり、LightGBMはKaggleなどの機械学習のコンペでもよく用いられる高精度を実現しやすいアルゴリズムになります。
それでは、実際にこの二つを選択しましょう!画面上の【サポートされているすべてのモデルを使用する】のチェックを外し、アルゴリズムをLogisticRegressionとLightGBMの二つを選択します。
学習時間の最大値を設定する
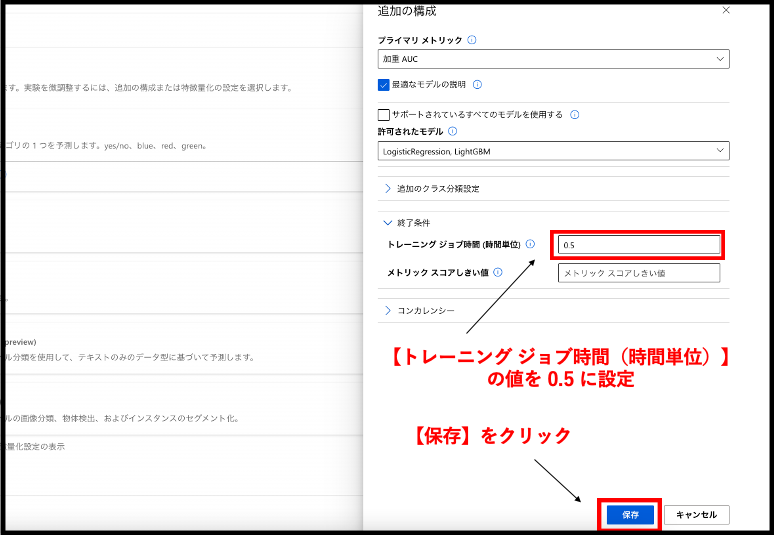
もう一つは、時間に関しての設定です。今回は、30分以上時間を要する場合は自動的に実行が終了するように設定しましょう。【終了条件】をクリックし、【トレーニング ジョブ時間(時間単位)】とあるところに0.5と入力してください。時間単位ですので、0.5時間で30分ですね!この設定ができたら、【保存】ボタンで元の画面に戻り、【次へ】をクリックしましょう。
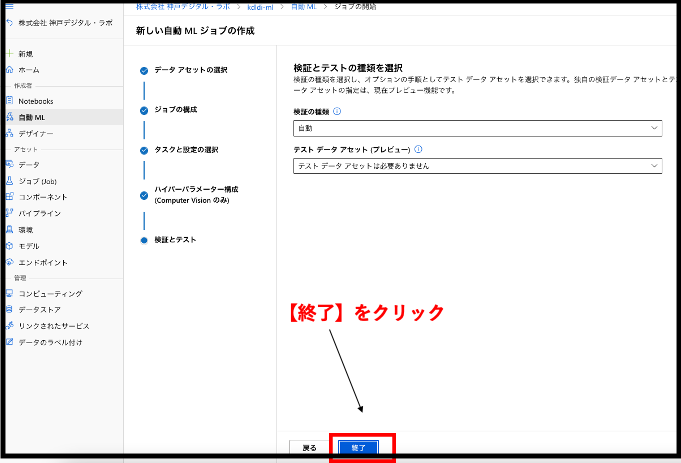
検証とテストの画面に遷移しました。こちらでは、データの割合をモデルの訓練・検証・テストの3段階でどのように振り分けるかを定義することができます。今回は、デフォルトの設定をそのまま利用して、テストの段階にデータを用意せず、訓練と検証の段階におけるデータの分割方法は自動とします。下の画面と同じことが確認できたら、終了をクリックしましょう。 注)検証とテストの違いが分かりにくいところですが、検証はモデルの訓練の途中で行われるものであり、テストはモデルの訓練が完全に終了してから行われるものになります。
終了ボタンを押すと、自動的に下図のような「実行中」の画面に遷移すると思います。こちらの学習には多少の時間がかかります。先ほどの最長の学習時間の設定した30分後にまた覗いてみてください。それまでは、優雅にコーヒでも淹れながらゆっくり結果を待ちましょう。実行が終了すれば、状態のところが「完了」に変更されます。
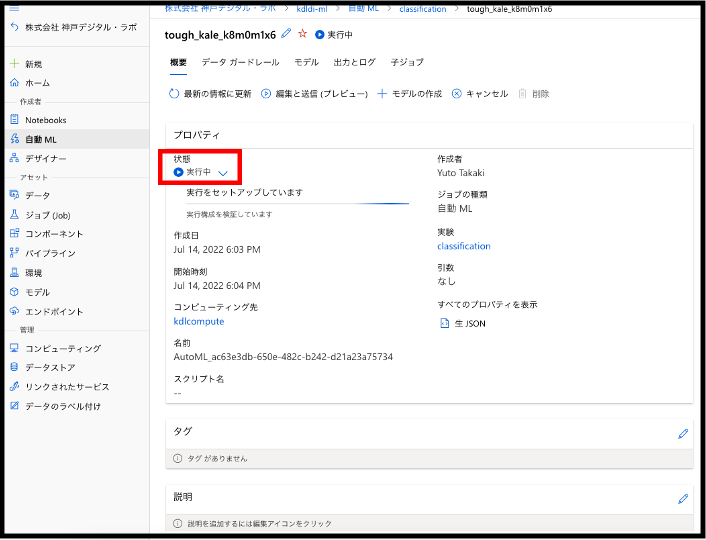
結果を見てみよう
実験が完成したら、モデルの詳細を見てみましょう。詳細を確認するには、【最適なモデルの概要】のウインドウにある【アルゴリズム名】をクリックします。
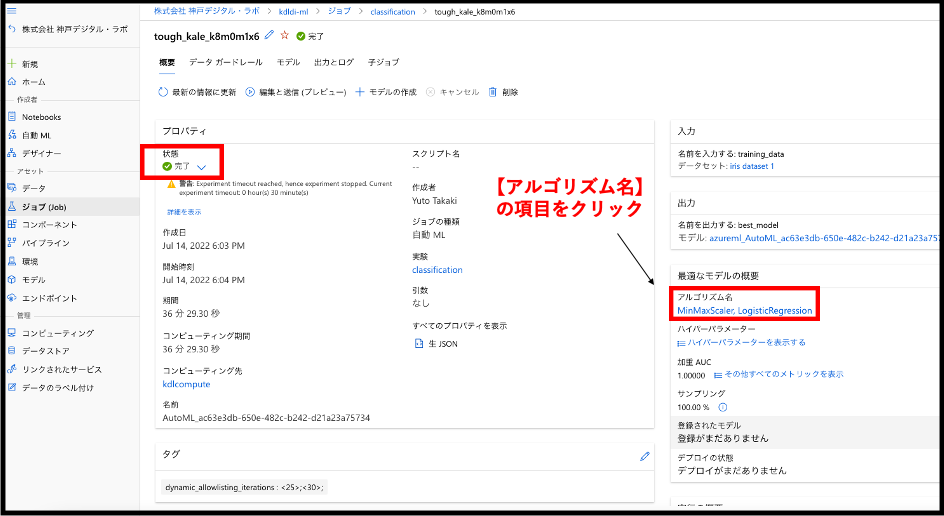
すると、下図のような画面が表示されると思います。次にページ上部にある、【メトリック】というタブを開いてみてください。
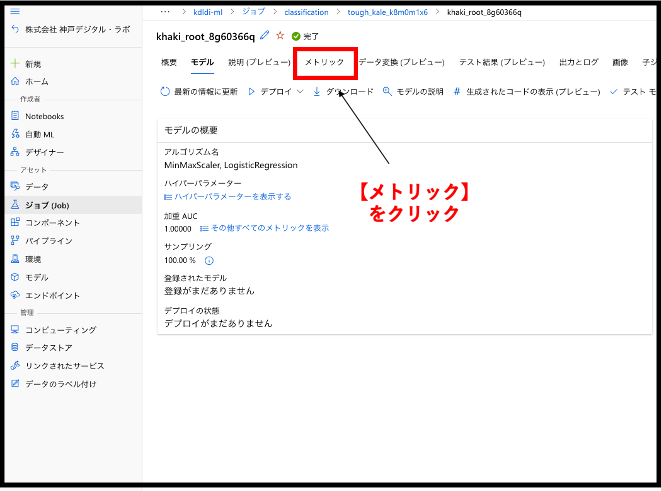
分類の精度をはかる指標がいくつか表示されると思います。AutoMLでは、豊富な評価指標(メトリック)の中から知りたい情報を、チェックボックスから選択できるようになっています。今回は、左のチェックリストのaccuracyとconfusion_matrixを有効にしてみたいと思います。accuracyはすべてのデータに対して、正しく判断できたデータ数を表す指標です。日本語では正解率と呼ばれます。また、confusion_matrixは日本語で混同行列と呼ばれ、実際のデータと予測されたデータの対応関係を示す指標です。今回は、accuracyを見ることでモデルの予測がどれくらいの正解率で、confusion_matrixによりモデルがどのような予測を行なっているのかを把握したいと思います。
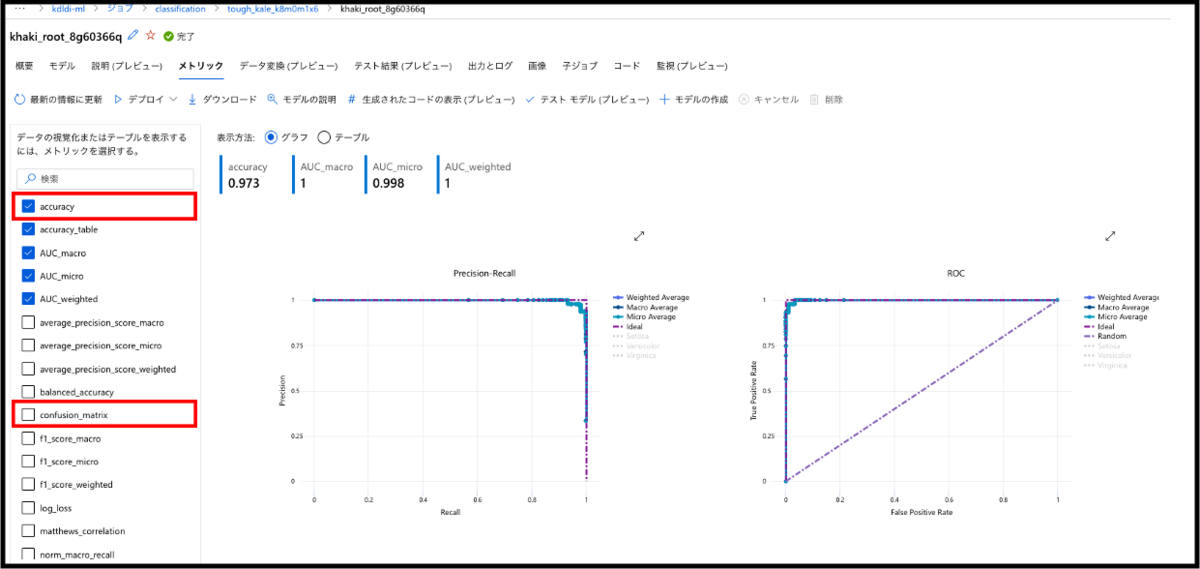
チェックをつけ終えると、以下のような画面に切り替わります。accuracyは0.973と表示されていますね!すなわち97.3%のデータに対して、作成したモデルが正しく予測を行なっているということです。かなり、高い正解率になっています!
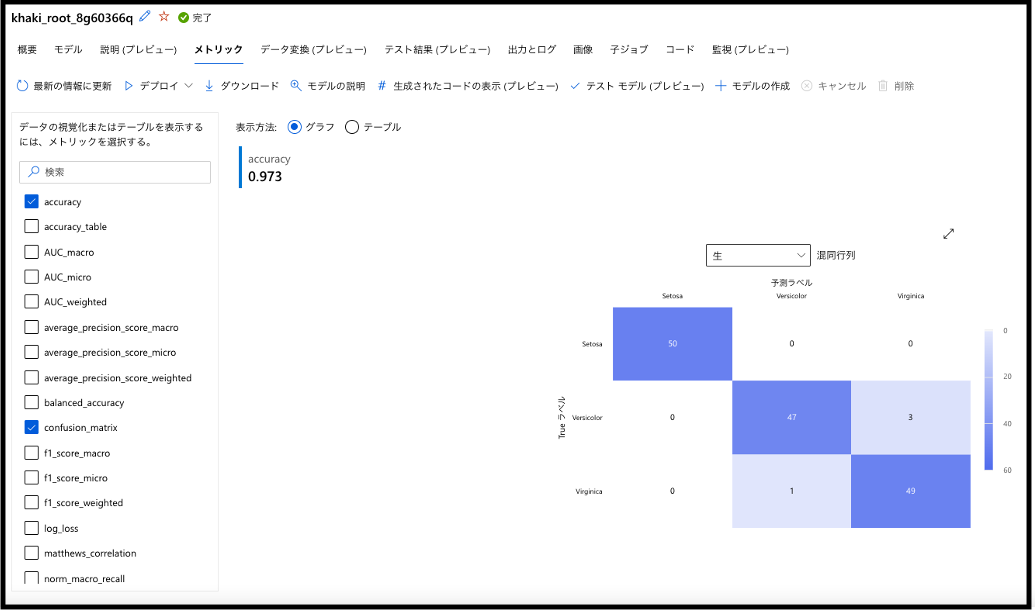
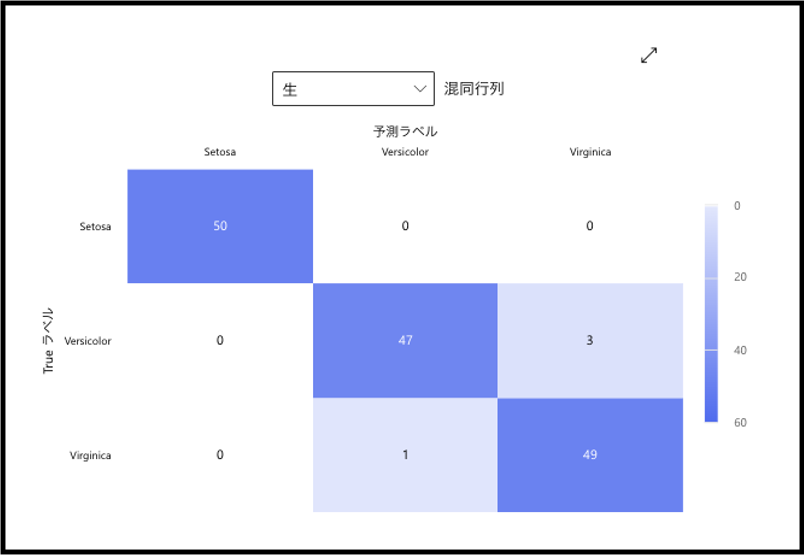
続いて、confusion matrixを見ていきます。列方向に実際の品種が並び、行方向にモデルの予測した品種が並んでいる行列となっています。詳しく見ていくと、Setosaに関しては全てのデータが正しく予測できていますね。それに対して、Versicolorは3個、Virginicaは1個間違えた予測されています。この二種類は特徴が少し似ているんでしょうか。いずれにしても、かなり良い感じで予測が可能なモデルが完成しました!
作成したモデルは、こちらのページからリアルタイムエンドポイントへのデプロイ、Webサービスへの配置、モデルのダウンロードが可能です。このようにAutoMLは、モデルを作成する以外の機能も充実しています!
まとめ
AzureのAutoMLを利用して自動機械学習を体験してみました。最終的には、かなり高い精度を誇るモデルが完成しましたね。今回は、実行時間をケアしてアルゴリズムを二つに限定しましたが、時間制限を設けずに他のアルゴリズムを試したり、すべてのメトリックを一つずつ観察してみるのもいいですね。
本記事をきっかけに、機械学習モデルを構築する手法の一つの選択肢として自動機械学習を検討してみてください。

データインテリジェンスチーム所属
データサイエンティスト。自然言語処理を中心としながら、その他の非構造化データや構造化データに関しても偏りなく扱います。こちらのブログでは、自然言語処理に関するトピックやAzureを中心としたクラウドを利用したデータ活用に関してのトピックを中心に様々な記事を発信していきます。
