ついに来ました!Azure OpenAI Service(以下 Azure OpenAI)が使えるようになりましたので、早速使い倒してみた記録を残していきたいと思います!!
が、その前に申請!
Azure OpenAIの一般利用が可能となりましたが、利用するためには事前審査をパスする必要があります。こちらのページから申請を出して結果を待ちます。
申請してから、利用までには約3週間程度かかりました。審査をパスするまでのインターバルは申込み状況によって左右されるので、あくまで一例としてとらえて頂ければと思います。
申請が通ったら、早速リソース作成!
Microsoft Azure PortalからOpenAIと検索してもらうと、図のようにアイコンが出てくるのでクリックしてください。

基本的にリソース作成方法は他のサービスと変わらないのですが、2023年3月現在では利用できるリージョンに制限があります。今回はデフォルトの「East US」を利用しています。価格レベルも「Standard S0」しか設定できません。
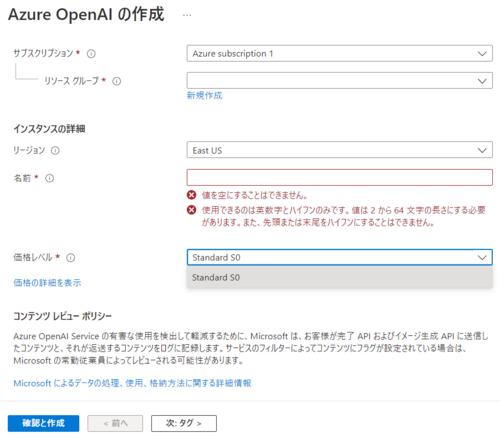
この辺りはサービスの拡大とともに変わってくるのと思うので、引き続き情報のキャッチアップをしておくと良いでしょう。
リソースグループの設定とインスタンス名の命名ができれば、一番下部にある「Azure OpenAIの倫理規定」に目を通しておき「確認と作成」ボタンを押下してリソース作成をします。
完成までは3分ほどかかるので、しばらく待機します....
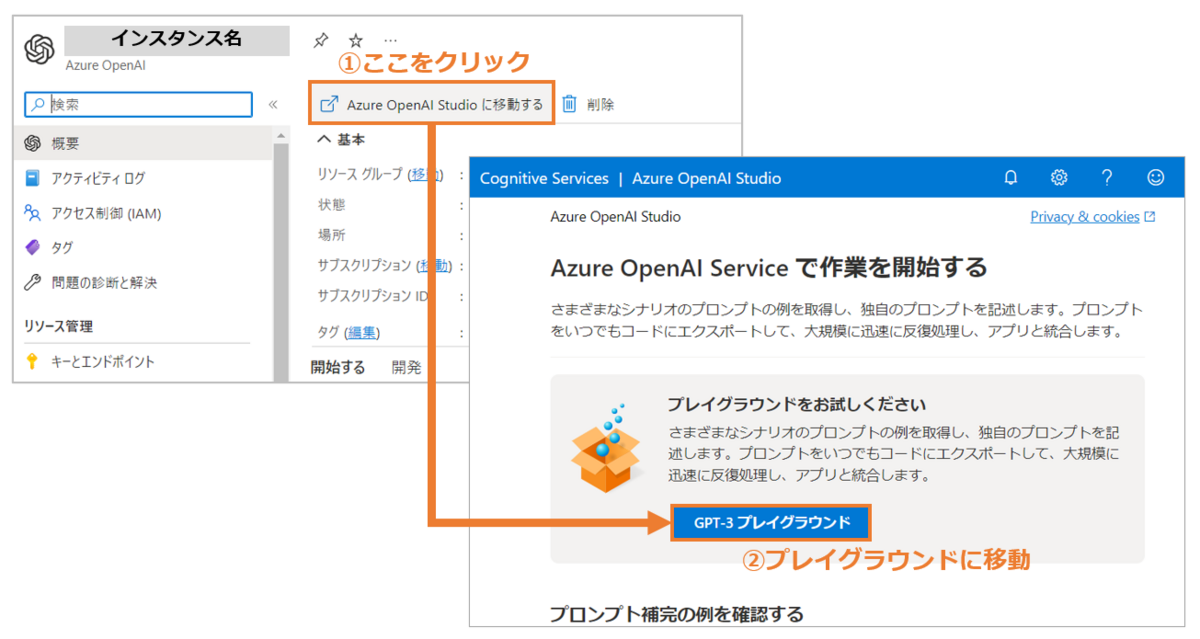
リソースが作れたら、一覧画面に表示されるのでクリックします。すると図の左側のような画面が表示されるので「Azure OpenAI Studioに移動する」というボタンを押してください。そうすると右側のような画面が表示されると思います。これが「Azure OpenAI Studio」になります。ここではテキストの要約や分類、SQL生成・文章生成等ができるようになります。まずは文書生成からやっていきたいと思います!
Azure OpenAIでできること
利用前の予備知識
Azure OpenAIを使う上で欠かせない概念の1つにモデルファミリがあります。かみ砕いて説明すると、モデルファミリはモデルの用途・目的を表すカテゴリのような概念です。と表現できます。様々なモデルがある中で最適なモデルを見つけやすくするための分類です。
モデルファミリの種類
| モデルファミリ名 | 目的 |
|---|---|
| GPT-3 | 言葉の理解と生成する ベースシリーズといわれることも。 |
| Codex | 言葉からコードを生成・理解をする |
| 埋め込み | テキスト文字列の関連性を測定する。 検索・クラスタリング・レコメンド・分類等が可能。 |
詳しくはこちらをご覧ください。
各モデルファミリごとに属するモデル種類が異なります。これらのモデルは、タスクに応じて能力と速度のレベルが異なるモデルが用意されています。
GPT-3モデル
言葉を理解・生成するGPT-3モデルでは4種類のモデルが用意されています。実験時は一番能力が高いDavinciから始めることが推奨されています。プロトタイプが動作したら、アプリケーションの待機時間とパフォーマンスの最適なバランスでモデルの選択を最適化していきましょう。
| モデル | 特徴 |
|---|---|
| Ada | テキストの解析、住所変更などの特定の分類タスクの実行 多くのコンテキストを提供することでパフォーマンス改善ができる。 |
| Babbage | ドキュメント検索・セマンティック検索のランク付け 単純な分類などの簡単なタスク実行が得意 |
| Curie | 感情分類・Q&A(チャットボット)、翻訳などに最適。 |
| Davinci | 複雑な意図理解・要約・文章生成などクリエイティブなタスクが得意 |
Adaが最速で、Davinciが一番高精度となっております。 速度と精度はトレードの関係にありますが、多くのコンテキストを与えることで精度は改善することができるとされてます。
Codex
GPT-3モデルの子孫ですが、このモデルはGitHubから数十億行のパブリックコードと自然言語を学習用データとして用意しています。コーディング周りに特化したモデルといえます。
このCodexはPythonで最も能力を発揮しています。それ以外にもC#、JavaScript、Go、Perl、PHP、Ruby、Swift、TypeScript、SQL、シェルなど、12 以上の言語に精通しているそうです。
Codexモデルは次の2種類から選択できます。
Cushmanでコードの生成ができるので、基本的にはこちらを使うと良いでしょう。より複雑なことをしたい場合はDavinciに切り替えるといった用途になりそうです!
| モデル | 特徴 |
|---|---|
| code-davinci-002 | 最も能力が高い。少ない命令で実行ができ、最も良い結果を得られる。 ただし、強力なコンピューティング リソースが必要になる上に高速ではありません。 |
| code-cushman-001 | コード生成タスクに対応できる強力かつ高速なモデル。 Davinciより性能は劣るものの、高速で低コストです。 |
埋め込みモデル
埋め込みモデルは「類似性埋め込み、テキスト検索埋め込み、コード検索埋め込み」といったように目的に応じて機能が分かれています。いずれも自然言語を理解し、各目的に応じた数値ベクトルを返却します。
| モデル | ディメンション(返却されるベクトルの長さ) |
|---|---|
| Ada | 1024 |
| Babbage | 2048 |
| Curie | 4096 |
| Davinci | 12288 |
Azure OpenAIでは、既存のモデルを使うことはもちろんモデルを微調整することもできます。こちらについては後日ご紹介したいと思います!
モデルの利用準備
使うモデルが決まれば、使えるように準備をしていきます。Azure OpenAI Studioの左下にある「モデル」をクリックしてください。すると現在提供されているモデルがすべて出てくるので、使いたいモデルを選択して「モデルのデプロイ」と書かれているところをクリックしてください。数秒待つと使えるようになります。

モデルを使ってみる
では準備もできたので、早速使ってみたいと思います!!!!プレイグラウンドより「GPT-3」を選択すると、下の図のような画面が出てきます。「デプロイ」には先ほど設定したものを指定してください。

桜の開花に関する知らせを聞くようになってきたため、気持ちをフレッシュに「入社の挨拶メールの文面」を作ってもらいました!!結果やいかに....
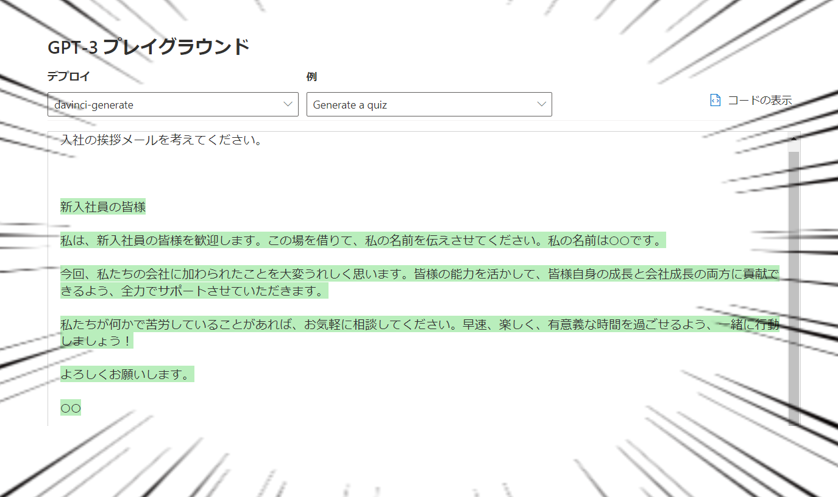 プロンプトが不十分だったのか新入社員が書いた文面ではなかったり、英語を直訳したような不自然さがあるなど課題は多々ありますが、日本語入力・日本語出力ができています!!!英語だけだと思ってたそこのあなたに朗報です!!!
プロンプトが不十分だったのか新入社員が書いた文面ではなかったり、英語を直訳したような不自然さがあるなど課題は多々ありますが、日本語入力・日本語出力ができています!!!英語だけだと思ってたそこのあなたに朗報です!!!
次回予告
次回は、どうすればより自然な日本語が出力されるようになるのか?そして右側にある「Parameters」という謎ツールなどに迫っていきたいと思います!!!
