データインテリジェンスチームの畑です。
こちらの記事は「Promptflow使って文書検索の仕組みを作ってみた!」の第二弾です。
独自の文書から質問・回答する仕組みをAzure Machine Learning Studioに追加されたPromptflowを使って実装します。
-----------------------------------------------------------------------------
第一弾:Promptflowを使うための準備編
第二弾:独自データを使ったQ&Aのフロー作成編
第三弾:質問・回答の精度向上&エンドポイントへのデプロイ編
-----------------------------------------------------------------------------
本記事では、「第二弾:独自データを使ったQ&Aのフロー作成」を進めていきます。第一弾をまだ読まれていない方は以下のブログを確認してください。
では、早速Azure Machine Learning Studioにアクセスしてフローを作成していきましょう!
フローの種類
Promptflowではユースケースに合わせたフローがいくつも準備されており、ベースとなるフローを修正していく形で開発を進められます。標準で準備されているフローの種類は大きくStandard、Chat、Evaluationの3つです。目的にあったフローをベースに開発をしましょう。
Standard(標準)
Q&Aや分類のフローです。入力から出力まで1度だけ実行されます。シンプルなフローから始めたい、とりあえず触ってみたいという場合はこちらを使いましょう。
Chat(チャット)
ChatGPTのように会話のキャッチボールをしたい場合はこちらを使います。Standardに会話機能を加えたもので、会話の履歴情報も踏まえて回答してくれます。
Evaluation(評価)
目標とする出力が明確な場合にこちらが使えます。入力と目標とする出力を事前に準備しておくことで、パフォーマンスの評価を自動で行うことができます。パフォーマンスの評価方法も様々準備されているので、気になる方はこちらのページをご覧ください。
具体的な活用例でいうと、質問に対して「はい」か「いいえ」の2択で回答するようなシンプルなQ&Aで正解率を出すことが可能です。プロンプトやLLMモデルを調整などフローを改善する際の評価軸として活用ができます。
今回は独自データを使ったQ&Aのフローを作成したいので、「Standard」の「Q&A on Your Data」を使ってみます。
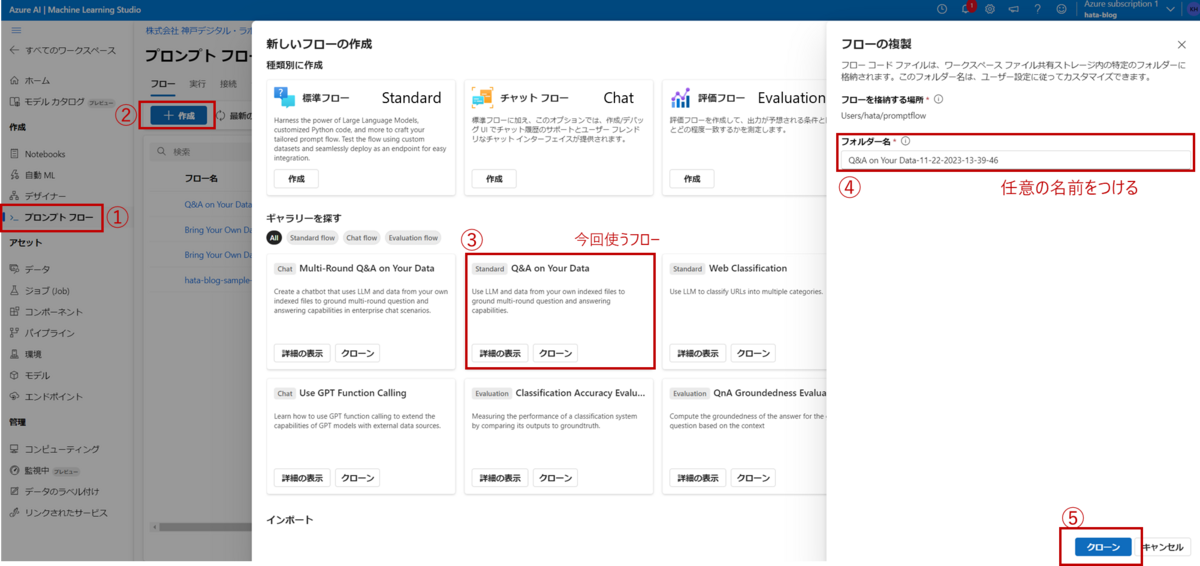
基本的な使い方
「Q&A on Your Data」のフローについて説明する前に、Promptflowの基本的な使い方を紹介します。フロー画面の各役割は以下の図の通りです。
役割ごとに詳しく見ていきましょう。
基本操作
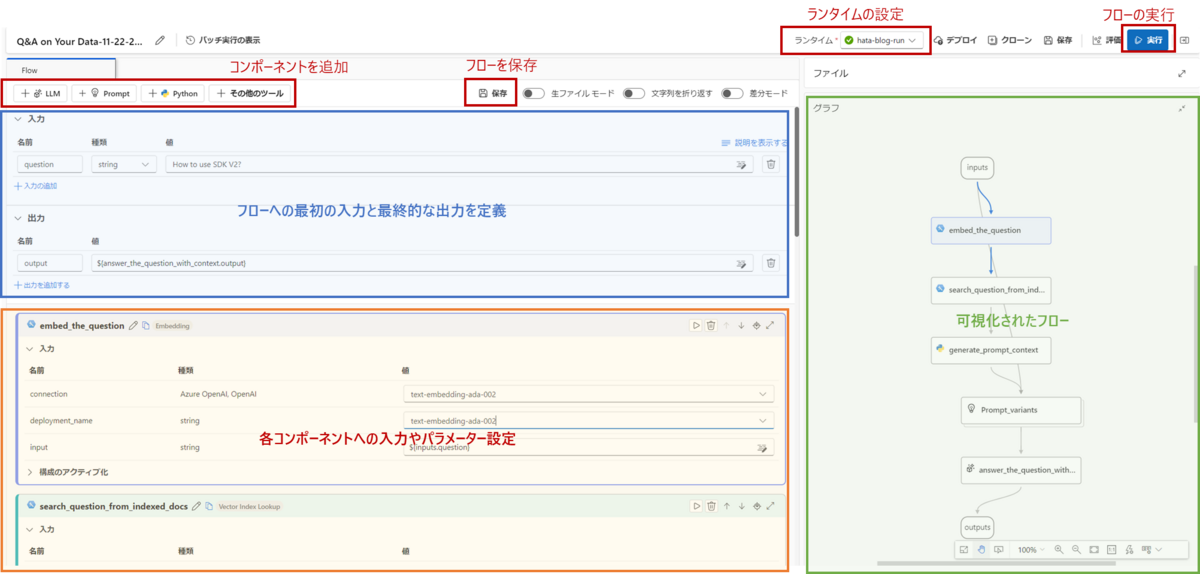
- コンポーネントを追加する
一番上に追加ボタンが準備されているので適当なものを選択しましょう。 - フローを実行する
まずコンピューティングから前回作成したコンピュータを起動します。その後、プロンプトフローからランタイムを設定し、準備ができたら実行ボタンを押します。 - 作業を終了する
保存ボタンを押して、ブラウザを閉じるだけです。コンピューティングで実行しているコンピュータを停止させるのを忘れないようにしましょう!

基本操作
入出力の設定
フローの最初の入力と最終的な出力はこちらで設定します。入力、出力ともに追加ボタンで増やすことが可能です。入力は任意で設定してください。出力の値は${コンポーネントの名前.output}の形で設定します。プルダウン形式で選択肢がでてくるので出力したいコンポーネントを選択します。

各コンポーネントの設定
入力から出力までの途中のフローはこちらで設定します。LLM、Prompt、Python、その他ツールの大きく4種類があり、それぞれの使いどころについて簡単にご紹介します。
LLM:AzureOpenAIにデプロイしたLLMモデルを使う際に追加します。
Prompt:LLMに入力するプロンプトを調整したい場合に追加します。1度の実行で複数のプロンプトをLLMに入力できるので、プロンプトでどうパフォーマンスが変わるのかを確認したいときに使います。
Python:他のコンポーネントで対応できない処理をしたい場合に追加します。データの整形やAzureの別サービスと連携したい場合など様々な用途で使います。
その他ツール:文書検索(RAG)の仕組みを作りたいなどLLMのよくあるユースケースをPromptflowで構築する場合に使います。入力した文章をベクトル化する機能、ベクトル検索で類似度の高いドキュメントを取得する機能など様々なコンポーネントが準備されているので、Pythonで追加したい処理を書く前に一度確認してみるといいでしょう。
これらのコンポーネントを必要に応じて追加・削除しながら開発を進めます。
入力の項目では使うデータやリソースの設定をします。コンポーネントによって入力項目は様々あり、追加で増やすこともできるので目的に応じて設定してください。

フローの可視化
フローの流れは自動的に可視化されます。コンポーネントはドラッグできますので、処理の流れをこちらをみながら作っていきましょう。
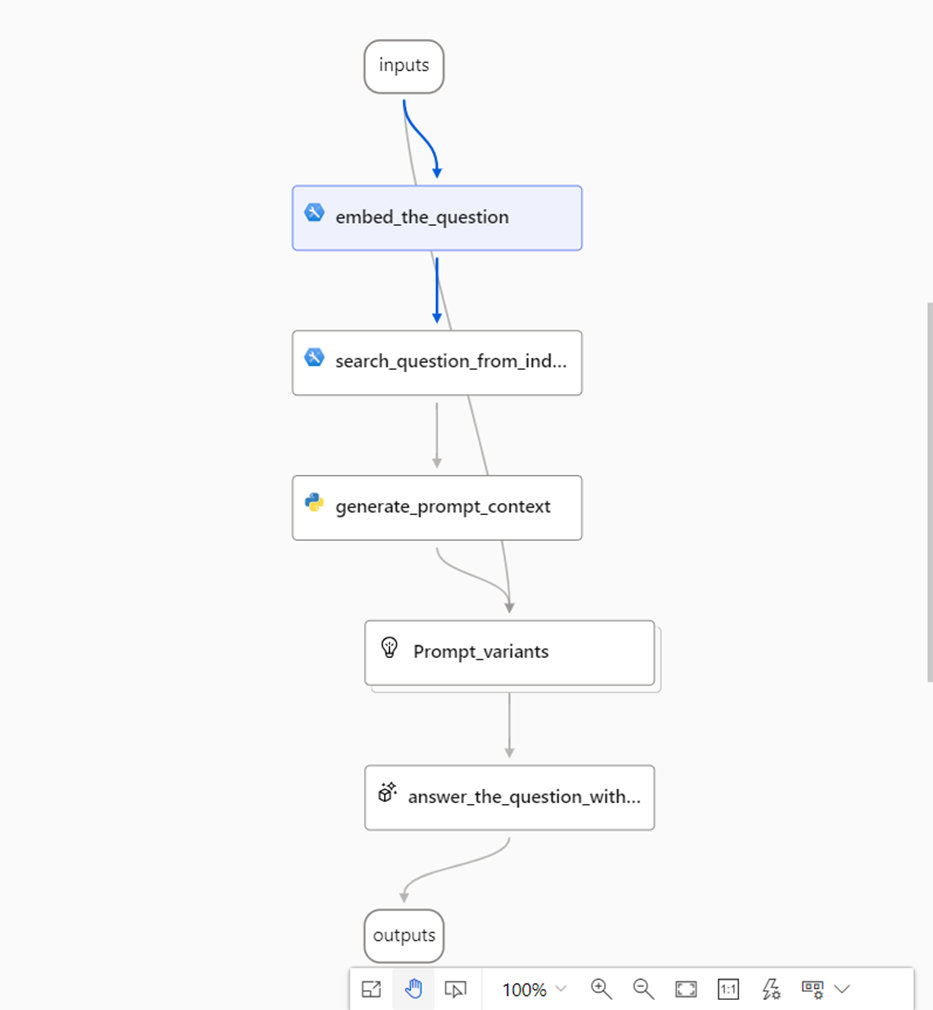
各コンポーネントについて
選択した「Q&A on Your Data」のコンポーネントと設定について順番に説明します。
embed_the_question
こちらは入力を数値化(以下、ベクトル化)するコンポーネントです。第一弾の準備編でデプロイしたAzure OpenAIのtext-embedding-ada-002を選択して使います。

search_question_from_indexed_docs
ベクトル化した質問を使って類似の文章を検索するコンポーネントです。今回はAzure AI Search(旧:Azure CognitiveSearch)に事前登録した文章の中から類似度が高いものをピックアップします。pathにAzure AI Searchのindexパスを貼り付けます。top_kは上位何件を取得するかを設定します。


generate_prompt_context
データ整形用のコンポーネントです。


- @toolデコレーターを実行したい関数に修飾する。
- 入力変数を関数の引数に設定する。
- 出力したいデータを関数の返り値に設定する。
標準で準備されているコードでは類似文章(Content)とソース(ファイル名)のみを抽出しています。別のデータが格納されているurlなど別のメタデータも使いたい場合はPythonコードを修正することで可能です。
# generate_prompt_context.py from typing import List from promptflow import tool from promptflow_vectordb.core.contracts import SearchResultEntity @tool def generate_prompt_context(search_result: List[dict]) -> str: def format_doc(doc: dict): return f"Content: {doc['Content']}\nSource: {doc['Source']}" SOURCE_KEY = "source" URL_KEY = "url" retrieved_docs = [] for item in search_result: entity = SearchResultEntity.from_dict(item) content = entity.text or "" source = "" if entity.metadata is not None: if SOURCE_KEY in entity.metadata: if URL_KEY in entity.metadata[SOURCE_KEY]: source = entity.metadata[SOURCE_KEY][URL_KEY] or "" retrieved_docs.append({ "Content": content, "Source": source }) doc_string = "\n\n".join([format_doc(doc) for doc in retrieved_docs]) return doc_string
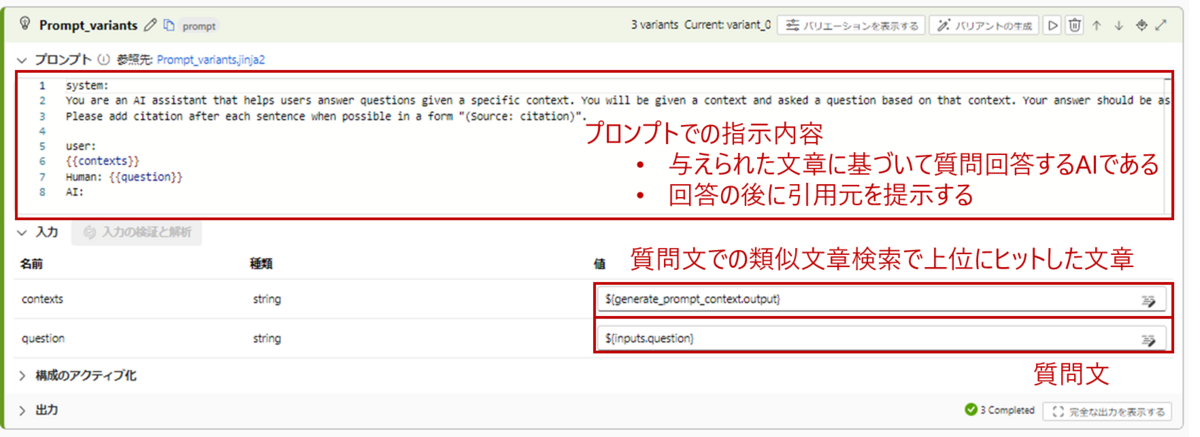
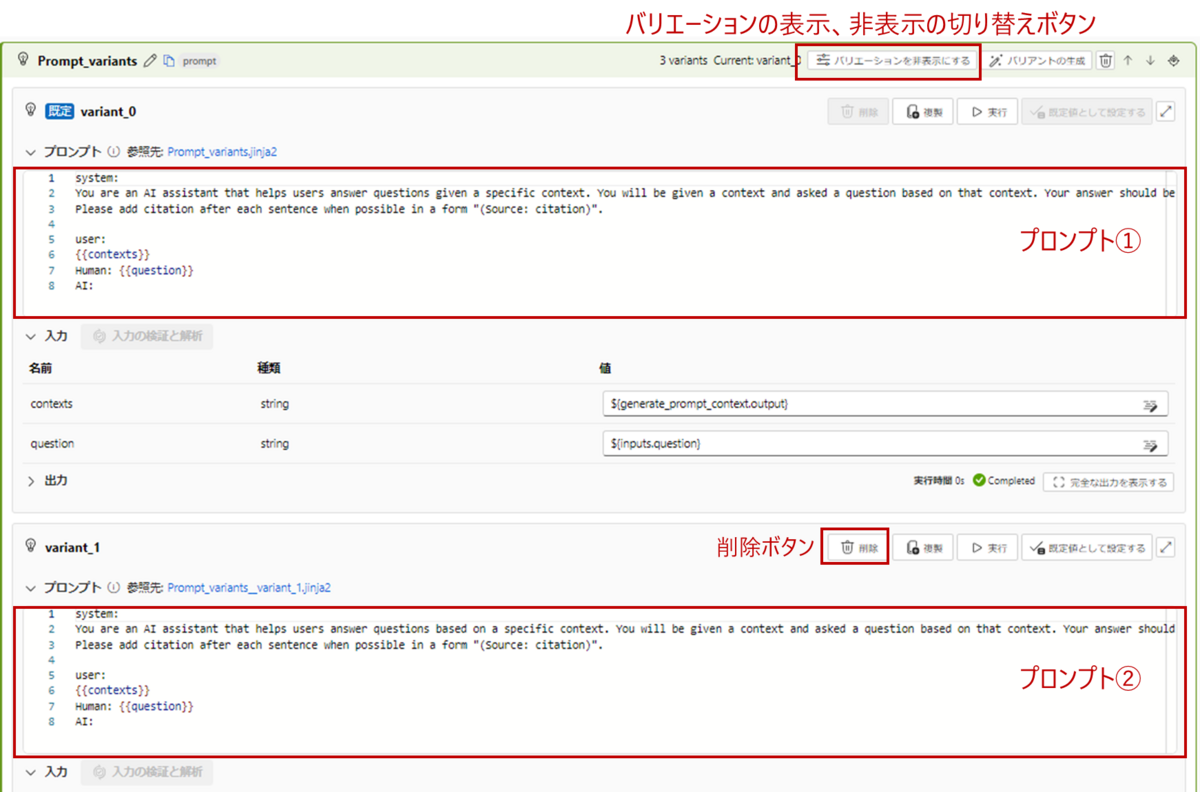
Prompt_variants
プロンプトを入力するコンポーネントです。英語で書かれていますが、日本語でも問題ありません。どんなプロンプトが書かれているか見ていきましょう。
System
初期設定では、「あなたは与えられた文章に基づいて質問に答えるAIアシスタントですよ。」「質問への回答と一緒に、参照情報をフォーマットに従って回答してね。」と書かれています。
このように出力の前提条件、制限などを書いて回答を制御します。
user
LLMモデルに与える文章を設定しています。ここで二重中括弧{{}}がでてきますが、こちらは変数を埋め込みたいときに使います。{{contents}}にはgenerate_prompt_contextで抽出した類似文章が入ります。実行時に具体的な情報に置き換えてカスタマイズするのに使用します。
Human
{{question}}には最初の質問が入ります。
answer_the_question_with_context
LLMの設定と入力を記載するコンポーネントです。Prompt_variantsで作成したプロンプトをそのまま記載しています。LLMモデルを使用するので、接続先や出力の条件を設定します。
接続・API・deployment_name
第一弾の準備編でデプロイしたモデル(gpt-4)を選択してください。デプロイしたモデルに合わせて選択します。
temperature
出力のランダム性を制御するパラメータで、0-1の値をとります。値を大きくするほどランダム性があがって、同じ質問をしても違う回答を返してきやすくなります。temperatureを小さくするほど、ランダム性が低くなり、質問に対して同じような回答を返してきやすくなります。ただし、完全に同じ出力結果になるとは限りません。
stop
出力を停止する文字列を指定します。出力したくない文字列があれば、こちらに指定すると出力しないようにすることが可能です。
max_tokens
出力する文章の上限単語数を設定します。

これでフローの設定は完了です。
フローの実行
最後に実行ボタンを押して、質問回答させてみます。ブログの中でたびたび登場する物体検出モデルのYOLOについて聞いてみました。実行した結果はこちら。
質問
YOLOについて教えて
回答
YOLOXは2021年に発表されたYOLO系の物体検出モデルです。YOLOv5・v8と比較するとモデルの学習準備が大変なところもありますが、ライセンスもApache-2.0 licenseと商用利用しやすい点が今でも人気の理由の1つです。また、YOLOXはリアルタイム推論にも使用されます(Source: azureml://locations/*/blog_6.html).

ブログの内容からそれっぽい回答をしてくれました。参照元も一緒に回答してくれています。
前回準備したリソース関連の設定はしたものの、フローは一切変更せず質問・回答するRAGのシステムを作成できました!
次のブログでは、精度向上&エンドポイントへのデプロイに取り組みます。
この記事で生成AIに興味を持たれた方はお気軽にお問合せください。

データインテリジェンスチーム所属
元製造メーカー勤務。製品の不良検知を担当したことがきっかけとなり、データサイエンスに興味を持ちKDLへ。クラウドを利用したデータ活用に関してのトピックを中心に発信していきます。
