データインテリジェンスチームの畑です。
「AWSのBedrockとKendraを使ってRAGの仕組み作ってみた!~Terraform版~」の後編です。前編の記事を未読の方は下記からご覧ください。
前編では以下のアーキテクチャをTerraformで構築するためにコードを準備しました。
 後編ではRAGの仕組みを完成させます。
後編ではRAGの仕組みを完成させます。
Lambdaの環境準備と実行コードの作成
Lambdaの処理概要
Lambdaの実行コードでは以下の処理を実装します。
- 質問文でKendraに検索をかける
- Kendraの検索結果と質問内容を元にBedrockのClaudeモデルで回答の文章を生成する
- 回答をAPI-Gatewayに返す
Lambda内のコード解説
1. 質問文でKendraに検索をかける
import json import os import boto3 kendra = boto3.client("kendra", region_name="us-east-1") bedrock_runtime_client = boto3.client("bedrock-runtime", region_name="us-east-1") def get_retrieval_result(query_text: str, index_id: str) -> list[dict[str, str]]: """ Kendraに質問文を投げて検索結果を取得する Args: query_text (str): 質問文 index_id (str): Kendra インデックス ID Returns: list: 検索結果のリスト """ # Kendra に質問文を投げて検索結果を取得 response = kendra.retrieve( QueryText=query_text, IndexId=index_id, AttributeFilter={ "EqualsTo": { "Key": "_language_code", "Value": {"StringValue": "ja"}, }, }, ) # 検索結果から上位5つを抽出 results = response["ResultItems"][:5] if response["ResultItems"] else [] # 検索結果の中から文章とURIのみを抽出 extracted_results = [] for item in results: content = item.get("Content") document_uri = item.get("DocumentURI") extracted_results.append( { "Content": content, "DocumentURI": document_uri, } ) return extracted_results
コードの前半部分です。
boto3.client(<リソース>, region_name=<リージョン>)
各クライアントを初期化して、リクエストを投げる準備をしています。get_retrieval_result()
Kendraに質問文を投げて検索結果を取得する自前の関数です。
引数は質問文とKendraインデックスを指定するindex_idです。index_idはデータを検索するインデックスを指定するのに使います。もしKendraの検索対象を変更したい場合は、Lambdaの環境変数から手動で変更するか、Terraformで該当のコードを変更してください。index_idはGUI上では以下に記載されています。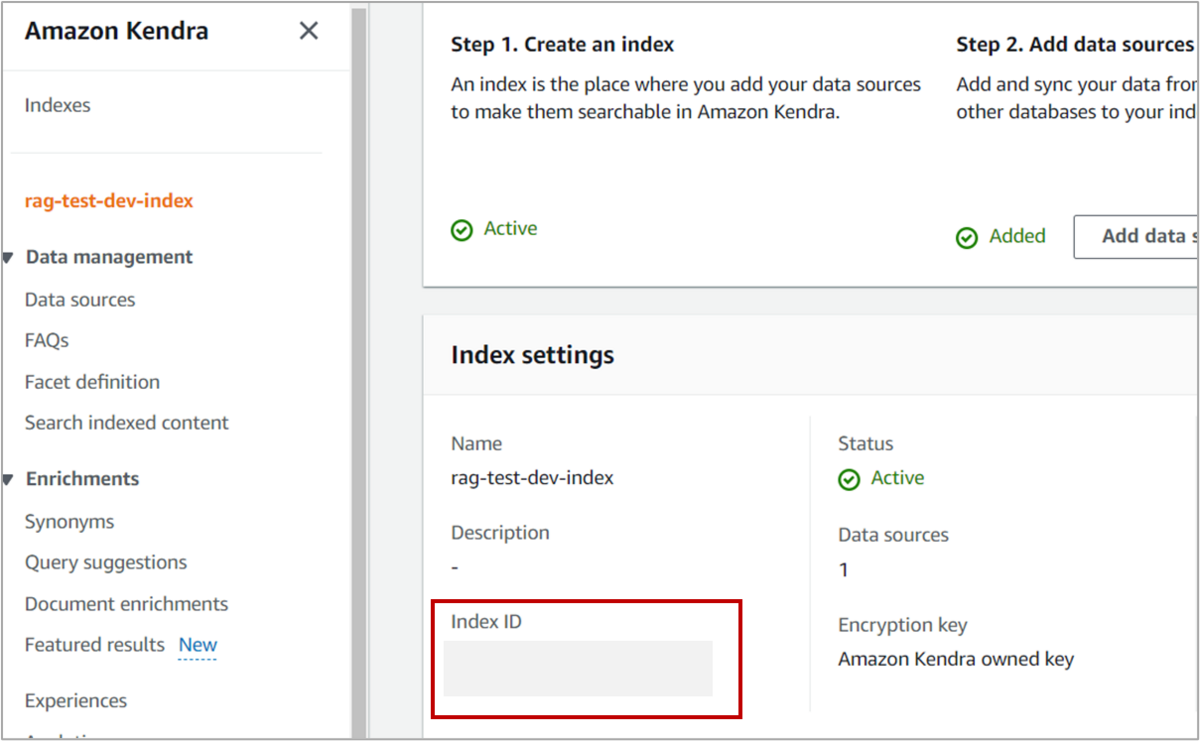
Index IDの記載場所 kendra.retrieve()
Kendraに検索をかけて結果を取得するAPIです。質問文で検索をかけています。詳しい書き方はこちらのドキュメントを確認してください。extracted_results
Kendraの検索結果の中から文章とURIのみを抽出します。
2. Kendraの検索結果と質問内容を元にBedrockのClaudeモデルで回答の文章を生成
def get_answer_from_bedrock( user_prompt: str, kendra_response: list[dict[str, str]] ) -> str: """ Kendraからの検索結果を元にBedrocから質問への回答を取得する Args: user_prompt (str): 質問文 kendra_response (list[dict[str, str]]): Kendraからの検索結果 Returns: str: 回答 """ # プロンプトの作成 prompt = f"""\n\nHuman: [参考]情報をもとに[質問]に適切に答えてください。 [質問] {user_prompt} [参考] {kendra_response} Assistant: """ # 各種設定 modelId = "anthropic.claude-v2" accept = "application/json" contentType = "application/json" body = json.dumps( { "prompt": prompt, "max_tokens_to_sample": 600, } ) # bedrockからのレスポンスを受け取る response = bedrock_runtime_client.invoke_model( modelId=modelId, accept=accept, contentType=contentType, body=body ) response_body = json.loads(response.get("body").read()) return response_body.get("completion")
get_answer_from_bedrock()
Kendraの検索結果と質問内容を元にBedrockに回答を生成させる自前の関数です。prompt
Bedrockに入力するプロンプトを作成しています。BedrockのLLMモデルに対する指示部分が”[参考]情報をもとに[質問]に適切に答えてください。”です。[参考]にKendraの検索結果、[質問]にAPIから取得した質問文が入るよう設定しています。modelId
使用するLLMモデルを記載します。今回は日本語の精度が高いと言われているClaudeモデルを使用します。モデルIDの書き方はこちらのドキュメントに詳しく書かれています。bodyのmax_token_to_sample
出力の最大トークン数を設定しています。bedrock_runtime_client.invoke_model()
Bedrockから質問回答の結果を受け取るAPIです。詳しい書き方はこちらのドキュメントに詳しく書かれています。
3. 回答をAPI-Gatewayに返す
def handler(event: dict, context) -> dict: """ Lambda ハンドラー関数 Args: event (dict): Lambda のイベント context : Lambda のコンテキスト Returns: dict: Lambda のレスポンス """ # Lambda のイベントからユーザーの入力を取得 # user_prompt = event.get("user_prompt") # API-Gateway からのリクエストを取得 body = json.loads(event["body"]) user_prompt = body["user_prompt"] # Kendra に質問文を投げて検索結果を取得 kendra_response = get_retrieval_result(user_prompt, index_id) # Bedrockからのレスポンスを受け取る response_body = get_answer_from_bedrock(user_prompt, kendra_response) return { "statusCode": 200, "body": json.dumps(response_body, ensure_ascii=False), }
handler()
API-Gatewayからリクエストを受け取りレスポンスを返す関数です。user_prompt
質問文です。リクエストはAPI-Gatewayを通してhandler()の引数であるeventに受け渡されます。APIのリクエストボディには{"user_prompt": "質問文"}をいれる想定です。リクエストボディはevet['body']に格納されるので質問文をuser_promptに格納します。event.get("user_prompt")
Lambdaのテスト機能を使う場合の質問文取得コードです。APIでリクエストを送る場合と書き方が違うので注意してください。get_retrieval_result()、get_answer_from_bedrock()
Kendraへの検索、Bedrockでの回答生成を行っている関数です。
以上が、Lambda関数の実行コードの説明でした。lambda.pyとして保存しましょう。
Lambdaにライブラリをアップロードする準備
lambda.py内で必要なライブラリをインストールし、Terraformでデプロイ時にLambdaへアップロードします。準備としては、作成したlambda.pyとrequiremant.txtをmodules/lambda/srcに配置するだけです。フォルダ構成は以下です。
root
├─・・・
└─modules
├─lambda
│ ├─main.tf
│ ├─variables.tf
│ ├─outputs.tf
│ ├─src
│ │ ├─requirements.txt
│ │ └─lambda.py
│ └─upload
│
└─・・・
requirement.txtにはKendraとBedrockを動作させるのに必要なboto3とurllib3==1.26.15を記載します。
boto3 urllib3==1.26.15
これで準備完了です。
TerraformでどのようにLambdaの実行環境を構築しているか以下に説明を載せています。興味のある方は以下の解説を読んでください。不要な方はデプロイに進みましょう。
Lambdaの実行環境構築
# requirements.txtを元にLambda関数に必要なライブラリをインストールする resource "null_resource" "pip_install" { triggers = { "requirements_diff" = filebase64("${path.module}/src/requirements.txt") } provisioner "local-exec" { command = "pip install -r ${path.module}/src/requirements.txt -t ${path.module}/src" } } # Lambda関数の実行に必要なファイルをzip化する data "archive_file" "lambda" { depends_on = [null_resource.pip_install] type = "zip" source_dir = "${path.module}/src" output_path = "${path.module}/upload/lambda.zip" } # Lambdaレイヤーを作成する resource "aws_lambda_layer_version" "lambda_layer" { filename = "${data.archive_file.lambda.output_path}" layer_name = "lambda" compatible_runtimes = ["python3.9"] } # Lambda関数のリソースを作成する resource "aws_lambda_function" "lambda" { filename = data.archive_file.lambda.output_path function_name = "${var.resource_prefix}_lambda" role = var.lambda_role_arn handler = "lambda.handler" source_code_hash = data.archive_file.lambda.output_base64sha256 runtime = "python3.9" timeout = 60 environment { variables = { BUCKET_NAME = var.bucket_name, INDEX_ID = var.index_id } } depends_on = [var.log_group_lambda] } # Lambda関数の実行権限を設定する resource "aws_lambda_permission" "lambda_permit" { statement_id = "AllowAPIGatewayGetTrApi" action = "lambda:InvokeFunction" function_name = aws_lambda_function.lambda.arn principal = "apigateway.amazonaws.com" source_arn = "${var.api-execution-arn}/*/POST/*" }
resource "null_resource" "pip_install"
必要なライブラリをローカルにインストールしています。data "archive_file" "lambda"
lambda/srcフォルダ内のすべてのファイルをzip化してuploadフォルダに出力します。ローカルにインストールしたライブラリとlambda.pyがzip化されています。resource "aws_lambda_layer_version" "lambda_layer"
filenameでLamabda関数のリソース作成時に作成したzipファイルのパスを指定します。resource "aws_lambda_function" "lambda"
API-GatewayからLambda関数を実行できるよう権限を設定しています。
デプロイ
以下のコマンドを実行して、構築されるリソースについて確認しましょう。
terraform plan -var-file envs/terraform.tfvars
terraform plan
リソースをデプロイする前に、変更点を確認するコマンドです。大きな変更となると、デプロイにも時間がかかるので、事前に想定通りの変更になっているか確認しましょう。文法ミスなどもここでエラーがでます。-var-file envs/terraform.tfvars
変数を記載したファイルのパスを指定しています。
確認して問題がなければ、下記のコマンドでデプロイ実行しましょう。
terraform apply -var-file envs/terraform.tfvars
terraform apply
リソースをデプロイするコマンドです。
Kendraへのデータ登録
ブログのデータをKendraで検索できるようにGUI上で作業します。
1. Kendraのデータソースに指定したS3のバケットへブログのデータをアップロードする。
データソースに指定したバケットはここから確認ができます。
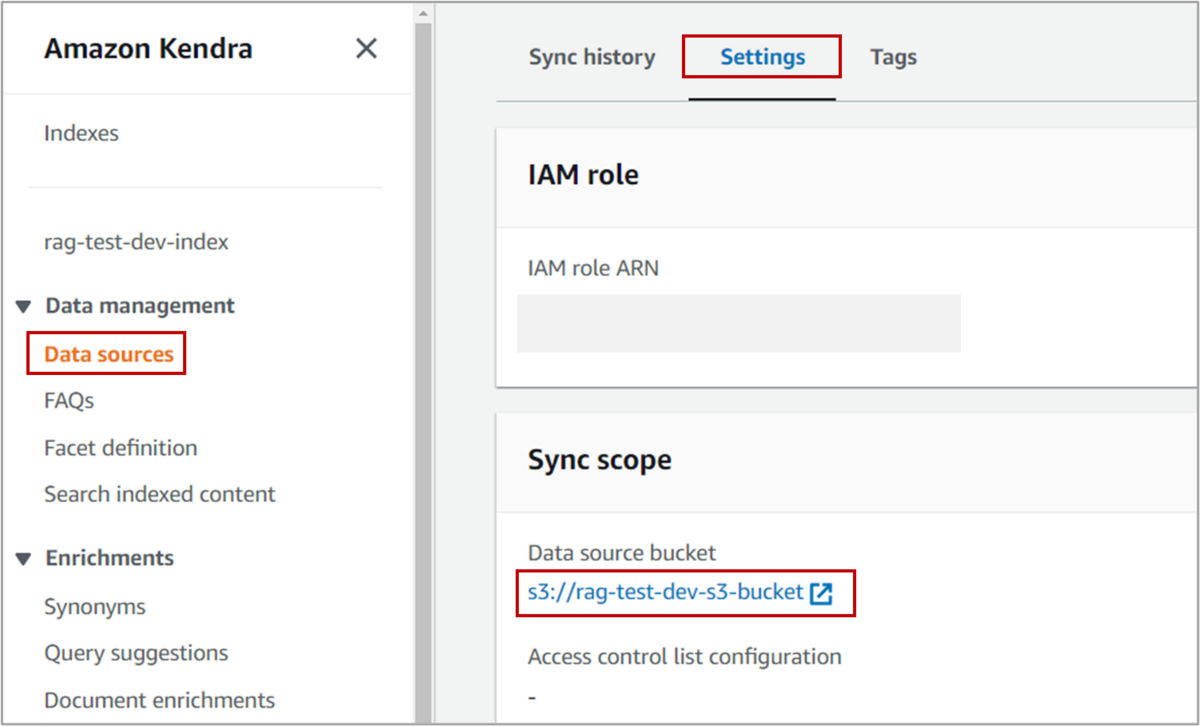
2. KendraとS3のバケットを同期する
Kendraにアクセスして該当のindexのData sourcesからSync nowボタンを押すとS3バケット内のファイルがすべてインデックスに登録されます。少し時間がかかるので完了まで待ちましょう。

REST APIで質問に対する回答を取得
API-GatewayにアクセスしてベースURLをメモします。

POST https://*********.execute-api.us-east-1.amazonaws.com/****/ HTTP/1.1
content-type: application/json
Accept: application/json
{
"user_prompt": "YOLOについて教えて"
}
回答はこちら!
AWSのBedrockとKendraで作成したRAGの回答
回答:YOLOはYou Only Look Onceの略で、1回のForward Propagationで画像全体の物体検出を実現する物体検出アルゴリズムです。特徴は高速でリアルタイム検出が可能、単一のニューラルネットワークで完結するシンプルな構造です。Ultralytics社のYOLOv8は、最新のYOLOモデルの1つで、少ないコードで高精度の物体検出ができるのが特徴です。
AzureのPromptflowと質問・回答を比べて見ましょう。
AzureのPromptflowで作成したRAGの回答
回答:YOLO(You Only Look Once)は、物体検出のための深層学習モデルの一つです。画像内の物体の位置とそのクラスを同時に検出することができます。YOLOはその名の通り、画像を一度だけ見ることで物体の位置とクラスを特定します。これにより、リアルタイムでの物体検出が可能となります。YOLOはその高速性と精度から、自動運転やビデオ監視などの分野で広く利用されています。また、YOLOにはいくつかのバージョンがあり、YOLOv5やYOLOXなどが存在します。
少し文章は違いますが、共通して以下のことが回答から読み取れます。
- YOLOはYou Only Look Onceの略であること
- 検出した物体の位置と名称を同時検出できるアルゴリズムであること
- 高速でリアルタイム検出が可能なこと
- YOLOのモデルにバージョンがあること
Promptflowの回答が、上記に加えて利用用途まで答えてくれているのが大きな違いでしょうか。どちらの精度が高いか判断が難しいところです。今回の結果だけ見るとあまり大きな違いはありませんでした。ブログで作成した以外にもRAGを構築するアーキテクチャは色々あるので、コストや使いやすさ、普段使用しているクラウド等、自分の条件に合うものを探して作ってみてください。
お困りの際はぜひお気軽にご相談ください。
今回で「AWSのBedrockとKendraを使ってRAGの仕組み作ってみた!~Terraform版~」の連載は終了です。
この記事で生成AIに興味を持たれた方はお気軽にお問合せください。

データインテリジェンスチーム所属
元製造メーカー勤務。製品の不良検知を担当したことがきっかけとなり、データサイエンスに興味を持ちKDLへ。クラウドを利用したデータ活用に関してのトピックを中心に発信していきます。
