株式会社神戸デジタル・ラボ DataIntelligenceチームの原口です。
前回は、構築したモデルをグラフ・正答率・混同行列を用いて評価しました!
もう一度内容を確認したい方は、以下の記事をご覧ください。
連載を最初から読みたい方は、以下の記事をご覧ください。
【第1回 基礎実装編】PyTorchとCIFAR-10で学ぶCNNの精度向上 - 神戸のデータ活用塾!KDL Data Blog
今回はAIモデルに「ひと手間」加えることで、過学習を抑制します!
前回の問題点
前回モデルの精度評価を行った結果、構築したモデルが途中から過学習傾向にあることが分かりました。
ここで過学習について振り返っておきましょう!
過学習とは、AIモデルが学習データに適合しすぎることで、未知のデータに対して精度が低下してしまう状態を指します。(詳しくは前回記事をご覧ください!)
前回は過学習の対策として、過学習に転じた段階で学習をストップする手法をご紹介しました。
しかし、この手法はモデルの汎化性能が最も高くなった段階で学習を止めるもので、過学習の根本的な解決方法ではありませんでした。
そこで今回は、AIモデルにDropoutという手法を適応することで過学習しにくいモデルに変更し、さらなる精度向上を図ります!
Dropoutとは?
Dropoutと呼ばれる手法は2014年に、Geoffrey Hintonらによって発表されました。(論文はこちら)
ではその中身を見ていきましょう!
過学習が起こる仕組み
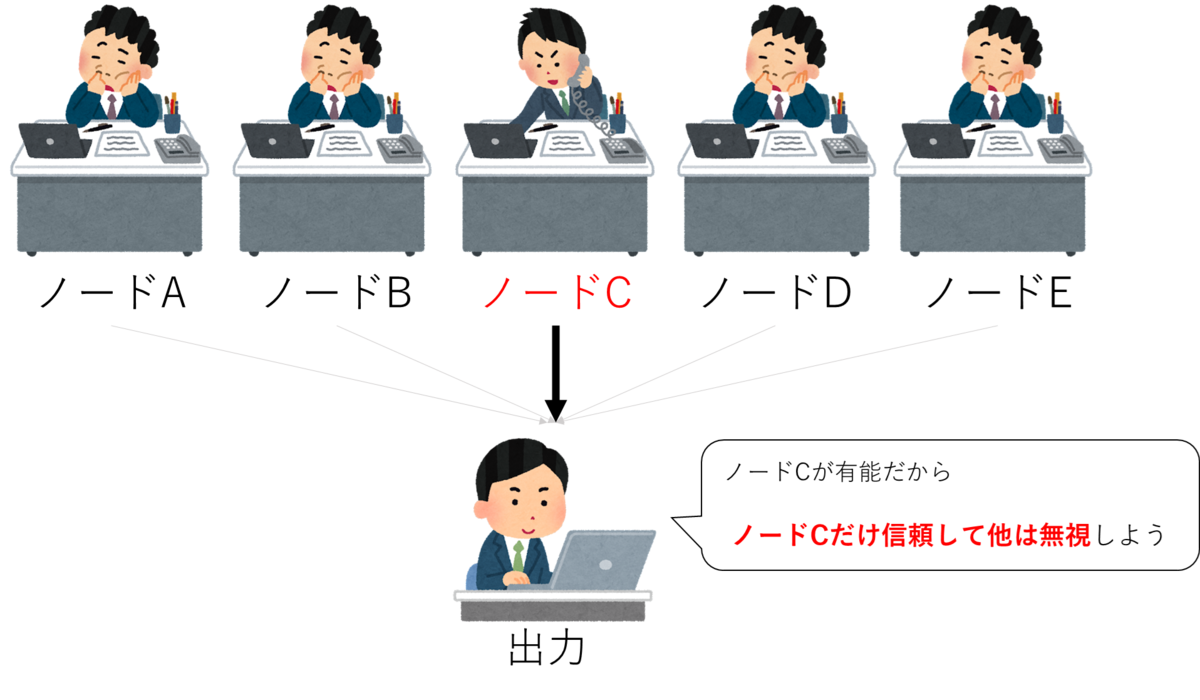
まずは過学習が起こる仕組みについて説明します。
上図のネットワークでは、あるデータにおいてAIモデルが予測を出力する際に、重要となる特徴の抽出を得意とするノードCが存在します。
この場合、AIモデルはノードCが抽出する特徴を重視し、ノードCの抽出結果を用いて出力を調整します。
一方で、ノードCと比較してこのデータの特徴の抽出が不得意なその他のノードは、出力の調整に使われることが少なくなってしまいます。

この状態で違う特徴を持つデータが入力されると、ノードCの得意・不得意にかかわらず、AIモデルはノードCの抽出結果を用いて出力を調整するため、正しい出力ができず精度が落ちる可能性があります。
この状態を、過学習と呼びます。
こういった、一つのノードだけが重要視される問題を解消するために、Dropoutは考案されました!
Dropoutの仕組み
Dropoutでは、利用できるノードを学習ごとに制限します。


上図では、1回目の学習でAとD、2回目の学習でAとCとEのノードを利用してAIモデルは予測をします。
このように、様々なノードをランダムに組み合わせて学習することで、特定のノードだけを重視する偏った学習が行われなくなります。
これにより、各ノードから総合的判断ができ、不得意な個所を他のノードが補えるようになるので汎化性能が向上します!
いざ実装!
では前回のモデルにDropoutの仕組みを追加実装します!
Dropoutのドキュメントはこちらです。
モデル名は新たにDropoutModelと命名し、構築していきます。
class DropoutModel(nn.Module): def __init__(self): super().__init__() self.conv1 = nn.Conv2d(3, 6, 5) self.pool = nn.MaxPool2d(2, 2) self.conv2 = nn.Conv2d(6, 16, 5) self.dropout_1 = nn.Dropout(0.5) #新しく追加した箇所 self.fc1 = nn.Linear(16 * 5 * 5, 120) self.dropout_2 = nn.Dropout(0.5) #新しく追加した箇所 self.fc2 = nn.Linear(120, 84) self.dropout_3 = nn.Dropout(0.5) #新しく追加した箇所 self.fc3 = nn.Linear(84, 10) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = torch.flatten(x, 1) x = self.dropout_1(x) #新しく追加した箇所 x = F.relu(self.fc1(x)) x = self.dropout_2(x) #新しく追加した箇所 x = F.relu(self.fc2(x)) x = self.dropout_3(x) #新しく追加した箇所 x = self.fc3(x) return x
新しく追加した箇所にコメントを付けています。
Dropoutを適応する場所は様々考えられますが、今回は過学習が起こりやすいと言われている全結合層付近に導入しました!
学習
では学習を実行していきましょう!
各モデル(BaseLineModel、DropoutModel)の実行結果を保存するために、前回まで利用していたコードを改修しています。
def show_score(epoch,max_epoch,itr,max_itr,loss,acc,is_val=False): print('\r{} EPOCH[{:03}/{:03}] ITR [{:04}/{:04}] LOSS:{:.05f} ACC:{:03f}'.format("VAL " if is_val else "TRAIN",epoch,max_epoch,itr,max_itr,loss,acc*100),end = '') def cal_acc(output,label): p_arg = torch.argmax(output,dim = 1) return torch.sum(label == p_arg) def Train_Eval(model,criterion,optimizer,data_loader,device,epoch,max_epoch,is_val = False): total_loss = 0.0 total_acc = 0.0 counter = 0 model.eval() if is_val else model.train() for n,(data,label) in enumerate(data_loader): counter += data.shape[0] optimizer.zero_grad() data = data.to(device) label = label.to(device) if is_val: with torch.no_grad(): output = model(data) else: output = model(data) loss = criterion(output,label) total_loss += loss.item() total_acc += cal_acc(output,label).cpu() if is_val != True: loss.backward() optimizer.step() show_score(epoch+1,max_epoch,n+1,len(data_loader),total_loss/(n+1) , total_acc/counter,is_val=is_val) print() return total_loss/(n+1) , total_acc/counter loss_dict = {} for is_drop in [False,True]: if is_drop: model = DropoutModel().to(DEVICE) else: model = BaseLineModel().to(DEVICE) criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters()) train_loss_list = [] val_loss_list = [] train_acc_list = [] val_acc_list = [] best_loss = None for epoch in range(EPOCHS): train_loss,train_acc = Train_Eval(model,criterion,optimizer,train_loader,DEVICE,epoch,EPOCHS) val_loss,val_acc = Train_Eval(model,criterion,optimizer,val_loader,DEVICE,epoch,EPOCHS,is_val=True) if best_loss is None or val_loss < best_loss: best_loss = val_loss torch.save(model.state_dict(), './best_ckpt.pth') train_loss_list.append(train_loss) train_acc_list.append(train_acc) val_loss_list.append(val_loss) val_acc_list.append(val_acc) if is_drop: loss_dict['drop_train_loss'] = train_loss_list loss_dict['drop_train_acc'] = train_acc_list loss_dict['drop_val_loss'] = val_loss_list loss_dict['drop_val_acc'] = val_acc_list else: loss_dict['normal_train_loss'] = train_loss_list loss_dict['normal_train_acc'] =train_acc_list loss_dict['normal_val_loss'] = val_loss_list loss_dict['normal_val_acc'] = val_acc_list
結果
それでは学習結果を表示してみましょう!
from matplotlib import pyplot as plt from random import randint, random plt.rcParams["font.size"] = 18 x = list(range(100)) val_len = len(train_data) - train_len y1_n = loss_dict['normal_train_loss'] y2_n = loss_dict['normal_val_loss'] y1_d = loss_dict['drop_train_loss'] y2_d = loss_dict['drop_val_loss'] y3_n = loss_dict['normal_train_acc'] y4_n = loss_dict['normal_val_acc'] y3_d = loss_dict['drop_train_acc'] y4_d = loss_dict['drop_val_acc'] # グラフの描画 fig = plt.figure(figsize = (20,10)) ax = fig.add_subplot(1, 2, 1) ax.set_title("loss") ax.set_xlabel('Epochs') ax.set_ylabel('Cross Entropy Loss') ax.plot(x, y1_n,label="normal_train") ax.plot(x, y2_n,label="normal_val") ax.plot(x, y1_d,label="drop_train") ax.plot(x, y2_d,label="drop_val") ax.legend() ax = fig.add_subplot(1, 2, 2) plt.ylim([0,1]) ax.set_title("Accuracy") ax.set_xlabel('Epochs') ax.set_ylabel('Accuracy') ax.plot(x, y3_n,label="normal_train") ax.plot(x, y4_n,label="normal_val") ax.plot(x, y3_d,label="drop_train") ax.plot(x, y4_d,label="drop_val") ax.legend() plt.show()

表示されたグラフは、左側がEpochに対する損失の推移を、右側がEpochに対する精度の推移を表しています。
まずは損失の推移を表したグラフ(左図)から見ていきましょう。
Dropoutを導入していないモデルでは、normal_train(青色の線)とnormal_val(オレンジ色の線)がEpochを追うごとに乖離が激しくなり過学習の傾向が見て取れます。
一方、Dropoutを導入したモデルでは、drop_train(緑色の線)とdrop_val(赤色の線)はほぼ同様の形をしており、過学習に陥っている様子はありません。
だた、Dropoutを導入していないモデルと比べて、損失の低下度合いが緩やかになってしまうことが分かります。
続いて正解率のグラフ(右図)も見てみましょう。
Dropoutを導入していないモデルでは、normal_val(オレンジ色の線)が50Epoch付近で最大精度を取り、その後低下していることが分かります。
一方、Dropoutを導入したモデルではdrop_val(赤色の線)が緩やかに上昇し続けていることが分かります。
100Epochの段階では、検証データに対してnormal_valが最も高精度ですが、学習を200Epoch、300Epochと進めることでDropoutModelの方が高精度になるとグラフから予測されます。
このようにDropoutを導入することで、過学習を抑制することができます。
一方で、Dropoutを導入することでAIモデルの学習速度が緩やかになることが分かりました。
Dropoutを導入する際は、学習時間が伸びてしまうため注意が必要です。
まとめ
今回は過学習対策としてDropoutをご紹介しました!
Dropoutを導入すると過学習を抑えられる反面、AIモデルの学習速度が緩やかになってしまう問題が発生しました。
この学習速度が緩やかになってしまう問題を解決するために、次回はAIモデルをより早く収束させることができる(かもしれない)BatchNormalizationについて説明します!

データインテリジェンスチーム所属
データエンジニアを担当しています。画像認識を得意としており、画像認識・ニューラルネットワーク系の技術記事を発信していきます
