株式会社神戸デジタル・ラボ DataIntelligenceチームの畑です。
このブログではAITRIOSとIMX500を使った物体検出に挑戦します。
今回の記事は、以下の記事の続きとなっていますので、未読の場合はこちらの記事をご覧ください。
前回、正しい検出結果が得られなかったため、追加で精度向上に取り組みます。
以下の流れの4.再学習&再撮影をやっていきます。
1. AIモデルの開発
2. IMX500へAIモデルをデプロイ
3. 撮影と検出結果の確認(前回の記事)
4. 再学習&再撮影(今回)
4. 再学習&再撮影
前回の考察
うまく物体検出できなかった理由について考察してみましょう。一般的に精度がでない要因と対策がこちらです。

上記の表と対応させて今回の学習データを確認してみます。

今回、各検出対象に対して学習画像を約15枚用意しました。また、学習モデルはAITRIOSに標準搭載されているMicrosoft Azureの画像認識サービスである「CustomVision」(以下、CustomVision)を使っています。CustomVisionの最低学習枚数は検出対象につき15枚のため、ぎりぎりの枚数で学習させていたことがわかりました。学習画像が足りなかった可能性がありそうです。
学習画像の品質が検出画像と異なる
学習画像の撮影と推論画像の撮影は同じ場所で行ったので、照明の違いはありません。明るさは統一できており問題ないと考えます。
撮影は様々な画角で行ったので、学習時と推論時の画角の違いはある程度カバーできるモデルになっていると考えています。ということで、画像の品質については一旦問題ないとしました。
学習時間が短い
Quickを選択したので学習時間は最低限に抑えていました。学習時間が短かった可能性があります。
モデルとの相性
学習枚数や画像品質を改善しても検出精度が上がらない場合は、別の物体検出モデル導入も検討が必要です。
今回の再学習で改善が見られなかった場合には検討します。
上記の考察から以下の二つの対策を実施してみます!
学習枚数を増やす
学習時間を長くする
データ準備
データの拡張(data Augmentation)
データを増やしたり、水増ししたりすることを機械学習の用語でデータの拡張(Data Augmentation)と呼びます。
単純に写真をたくさん撮って増やしてもいいのですが、今回は画像処理でデータを水増ししたいと思います。
水増し手法はデータの回転、反転、切り抜きを行いました。
データの水増しコード
import os import cv2 import random import glob # 水増しデータの格納フォルダを作成 new_folder_1 = "flip_rot" new_folder_2 = "frame_cut" os.makedirs(new_folder_1, exist_ok=True) os.makedirs(new_folder_2, exist_ok=True) # オリジナルデータのファイルを取得 folder_path = "./data" files = glob.glob(folder_path + "*.jpg") # データ水増し処理 for file in files: img=cv2.imread(file,cv2.IMREAD_COLOR) # 画像の回転 img_rot = cv2.rotate(img, cv2.ROTATE_90_CLOCKWISE) # 画像の反転 img_flip = cv2.flip(img, 1) # 回転,反転データの書き込み basename = os.path.basename(file) cv2.imwrite(".\\" + new_folder_1+'\\flip_'+basename,img_flip) cv2.imwrite(".\\" + new_folder_1+'\\rot_'+basename,img_rot) # 切り抜きサイズの設定 frame_size=(1000 ,2000) h,w=img.shape[:2] for i in range(5): #切り抜く際の始点(左上) x=random.randint(0,w-frame_size[1]) y=random.randint(0,h-frame_size[0]) #切り抜き処理 cut_pic=img[y:y+frame_size[1],x:x+frame_size[0],:] #切り抜き画像を保存 cv2.imwrite(".\\" + new_folder_2+'\\cut_pic'+ str(i)+"_" + basename,cut_pic)
こちらが水増ししたデータの一例です!

切り抜き処理で検出対象が映ってない画像は除外しています。
それぞれ元データ15枚に対して適応して、全部で学習データが70枚程度になりました。この画像を使って再学習を行います。
再学習
水増ししたデータをアノテーションをつけていきます。再学習の際は元のモデルに画像を追加して再学習が可能です。モデルのコンティニューからデータをアップロードしてアノテーション作業をします。
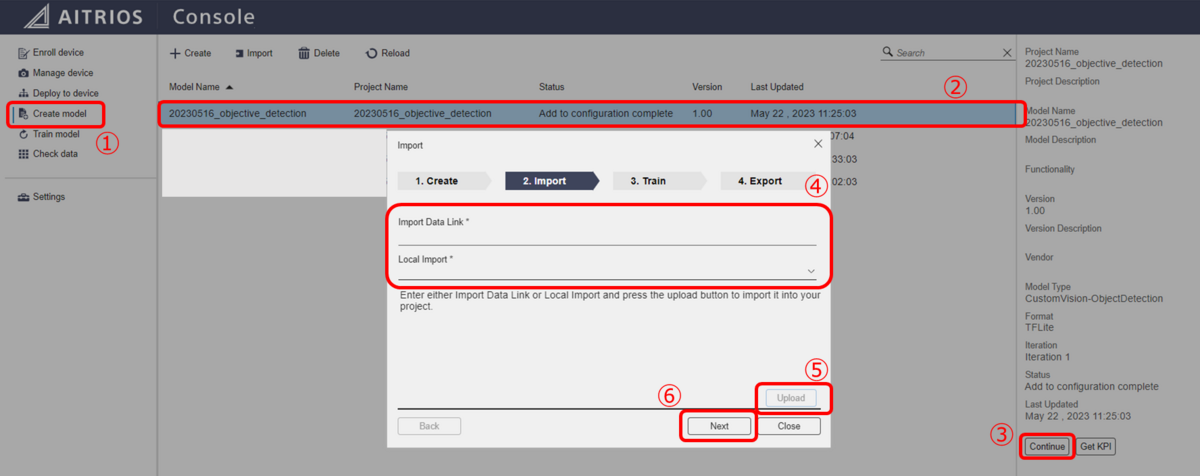
ブログ1と同じ作業なので、やり方がわからなくなった場合は下の記事を確認してください。
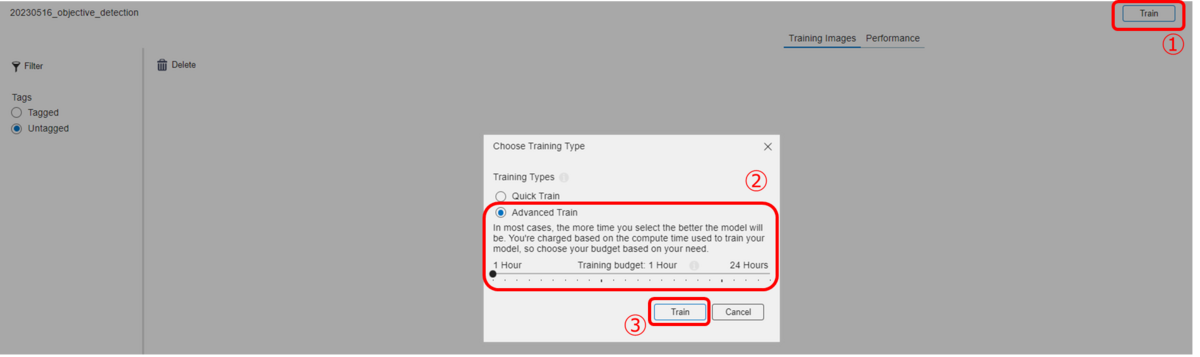
アノテーションをつけ終わったらTrainボタンを押します。ここでQuickTrainingではなく下の"Advanced Train"を押すと学習時間を決めることができるので設定して学習を開始します。今回は1時間に設定しました。
再撮影
学習が終わったら再度物体検出をやってみましょう。再学習させたモデルのデプロイや撮影方法はブログ②に詳しく書いているのでわからなくなった場合は下の記事を確認してください。 kdl-di.hatenablog.com
推論結果がこちら!

検出結果
検出結果をみると、ケーブル、紙コップ、ボールペンがそれぞれバウンディングボックスで囲われています。
検出物体のラベルも正しく判定されており、精度も約0.7~1.0と高い精度が出ています。
再学習と学習時間の延長で紙コップ、ボールペン、ケーブルを見分ける物体検出モデルができました! いつ使うねんと思いつつ、無事検出できてよかったです。 ぜひ使えそうなモデルをAITRIOSで作ってみてください。
これでAITRIOSで物体検出やってみたシリーズは終わりです! この記事でAITRIOSを使った業務改善に興味を持たれた方はお気軽にお問合せください。 また、AITRIOSに限らず画像AIモデル構築のPoC支援も行っています。 プロフィール下のバナーをクリックして詳細をご覧ください!

データインテリジェンスチーム所属
元製造メーカー勤務。製品の不良検知を担当したことがきっかけとなり、データサイエンスに興味を持ちKDLへ。クラウドを利用したデータ活用に関してのトピックを中心に発信していきます。
