株式会社神戸デジタル・ラボ DataIntelligenceチームの畑です。 このブログではAITRIOSとIMX500を使った物体検出に挑戦します。
今回の記事は、モデルの作成とデプロイ編の続きとなっていますので、未読の場合はこちらの記事をご覧ください。
物体検出をやってみよう(続き)
では早速続きを進めていきましょう!
以下の流れの3. 撮影と検出結果の確認をやっていきます。
1. AIモデルの開発(前回の記事)
2. IMX500へAIモデルをデプロイ(前回の記事)
3. 撮影と検出結果の確認(今回)
3. 撮影と検出結果の確認
撮影した画像の可視化や検出結果を確認するにはAPIを利用します。 ですので、まずAPIの利用準備から進めていきます。
3-1. APIの利用準備
AITRIOSのDeveloperサイトに、アプリケーション開発に使うGitHubのコードリポジトリ一覧があります。こちらを利用してAPIの利用準備を進めます。Python版とTypeScript版が用意されていますので、使いやすい方を選択してください。今回はPython版を使います。また、一般公開されていないリポジトリのため、クローンするにはアクセス権が必要です。こちらの問い合わせページからアクセス権を依頼しましょう。
アクセスが可能になったら、まずリポジトリをクローンします。今回使うのはこちらのリポジトリです。API経由でカメラを動かすサンプル コードや開発環境を構築するための構成ファイルが置かれていて、カメラを簡単に動かすことができます!次のコマンドを実行してクローンをしましょう。
git clone --recursive https://github.com/SonySemiconductorSolutions/aitrios-sdk-cloud-app-sample-python
クローンが終わったら、以下三つのフォルダに移動し、次のセットアップコマンドを実行します。
'aitrios-sdk-cloud-app-sample-python\.devcontainer\Dependencies\aitrios-sdk-console-access-lib-python\src'
'aitrios-sdk-cloud-app-sample-python\.devcontainer\Dependencies\aitrios-sdk-console-access-lib-python\lib\python-client'
'aitrios-sdk-cloud-app-sample-python'
python setup.py develop
これで必要なライブラリを使えるようになりました!
続いて、Consoleへのアクセスに必要な以下の認証情報を取得します。
・client_id
・client_secret

client_idの確認方法
AITRIOSのポータルからクライアントアプリ管理画面に進むと確認が可能です。
client_secretの取得方法
client_idと同じく、クライアントアプリの管理画面に進みます。「シークレットを発行する」で発行可能です。
発行したキーはページ遷移後に確認できなくなりますので、必ずメモしておきましょう。シークレットキーは最大2つまで発行ができます。
これで認証情報の取得ができました。
最後に、API疎通確認のため、API経由でカメラのデバイスIDを取得してみましょう。
Yamlファイルを以下のように作成して作業エリア直下に保存します。
console_access_settings: console_endpoint: "https://console.aitrios.sony-semicon.com/api/v1" portal_authorization_endpoint: "https://auth.aitrios.sony-semicon.com/oauth2/default/v1/token" client_id: "取得したclient_idを入力" client_secret: "取得したclient_secretを入力"
続いて、以下のコードを実行して接続されているカメラのデバイスIDを取得します。
import os import sys import warnings from console_access_library.client import Client from console_access_library.common.config import Config from console_access_library.common.read_console_access_settings import \ ReadConsoleAccessSettings def get_console_client(): """Get access information from yaml and generate ConsoleAccess client Returns: ConsoleAccessClient: ConsoleAccessClient Class generated from access information. """ setting_file_path = os.path.join(os.getcwd(), "console_access_settings.yaml") print(setting_file_path) read_console_access_settings_obj = ReadConsoleAccessSettings(setting_file_path) config_obj = Config( read_console_access_settings_obj.console_endpoint, read_console_access_settings_obj.portal_authorization_endpoint, read_console_access_settings_obj.client_id, read_console_access_settings_obj.client_secret ) client_obj = Client(config_obj) return client_obj client_obj = get_console_client()
デバイスID(sid-から始まる英数字32桁)が取得できれば完了です。
デバイスIDはこの後使うのでメモしておきます!
3-2. 推論付きの撮影
API経由でカメラを制御する準備が整いましたので、
お待ちかねの物体検出をやっていきましょう。
まず、推論の条件設定を行うjsonファイルを準備します。
{ "commands" : [ { "command_name": "StartUploadInferenceData", "parameters": { "Mode": 1, "UploadMethod": "BlobStorage", "FileFormat": "JPG", "UploadMethodIR": "MQTT", "NumberOfImages": 5, "UploadInterval": 100, "NumberOfInferencesPerMessage": 1, "MaxDetectionsPerFrame": 5, "ModelId":"作成したモデルの名前を入力", "PPLParameter": { "header": { "id": "00", "version": "01.00.00" }, "dnn_output_detections" : 64, "max_detections" : 5, "threshold" : 0.1, "input_width" : 320, "input_height" : 320 } } } ] }
ModelId
自身で作成したモデルの名前を入力するようにしましょう。
※今回は前回の記事で作成したモデルを使うので「20230316_objective_detection」と入力します。
NumberOfImages
推論する画像の枚数です。例えば"5"に設定すると、5枚の推論データと画像が保存されます。
0にするとAPI経由で停止させるまで推論が続きます。
その他のパラメータの役割はConsole ユーザーマニュアルの4.Appendixを参照してください。マニュアルがみれない場合はAITRIOSのポータルにログインしてから再度確認しましょう。
作成したjsonファイルはConsoleのSetting→Command Parameterからインポートします。
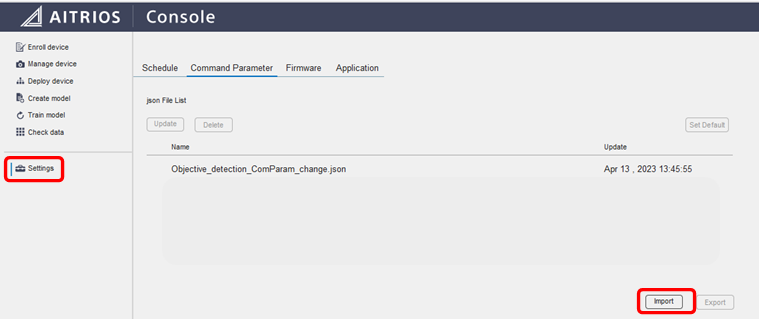
完了後、Manage deviceから今回使うデバイスを選択し、Setting→Command Parameter Fileから先ほどインポートしたjsonファイルを選択してBindingボタンをクリックします。
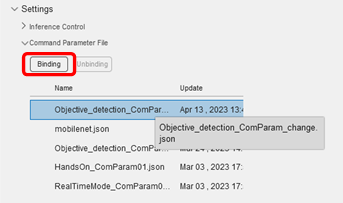
カメラで推論する準備ができました!
メモしたデバイスIDをdevice_idに入力し、推論コードを実行します。
device_id = "your id"
response = client_obj.get_device_management().start_upload_inference_result(device_id)
1枚5秒前後ですので、検出したいものを画角にいれて1分ほど待ちましょう。 これで推論付きの撮影が完了です。
3-3. 検出結果の確認
最後に検出結果を確認しましょう。
先ほどのresponseの中身から末尾の数字(撮影した日付と識別の番号)をメモします。
例)下記のresponseの場合は「20230413022930673」
DynamicSchema({'result': 'SUCCESS', 'outputSubDirectory': 'デバイスIDなどの情報/image/20230413022930673'})
メモした数字を下記のコードに入力して実行すると、検出結果、画像が取得できます。 検出結果、画像データがinference_dictに格納されました。
insight_obj = client_obj.get_insight()
inference_dict = insight_obj.get_last_inference_and_image_data(
device_id,
"20230413022930673",
)
ここから以下3つのステップで物体検出結果の表示に取り組みます。
・画像データの取得
・検出結果の取得
・画像に検出結果を重ねて表示
まずは画像データの取得です。
以下のコードを実行しましょう。
import io, base64 from PIL import Image img = Image.open(io.BytesIO(base64.decodebytes(bytes(inference_dict["image_data"]["images"][0]["contents"], "utf-8"))))
次に、検出結果の取得です。
pred = inference_dict["inference_data"]["inferences"][0]["O"]
predが推論結果ですが、シリアライズされているため、デシリアライズするコードを実行します。
import base64 from desirialize.ObjectDetection import object_detection_top, bounding_box, bounding_box_2d def get_deserialize_data(serialize_data): """Get access information from yaml and generate ConsoleAccess client Returns: ConsoleAccessClient: CosoleAccessClient Class generated from access information. """ buf = {} buf_decode = base64.b64decode(serialize_data) ppl_out = object_detection_top.ObjectDetectionTop.GetRootAsObjectDetectionTop(buf_decode, 0) obj_data = ppl_out.Perception() res_num = obj_data.ObjectDetectionListLength() for i in range(res_num): obj_list = obj_data.ObjectDetectionList(i) union_type = obj_list.BoundingBoxType() if union_type == bounding_box.BoundingBox.BoundingBox2d: bbox_2d = bounding_box_2d.BoundingBox2d() bbox_2d.Init(obj_list.BoundingBox().Bytes, obj_list.BoundingBox().Pos) buf[str(i + 1)] = {} buf[str(i + 1)]['C'] = obj_list.ClassId() buf[str(i + 1)]['P'] = obj_list.Score() buf[str(i + 1)]['X'] = bbox_2d.Left() buf[str(i + 1)]['Y'] = bbox_2d.Top() buf[str(i + 1)]['x'] = bbox_2d.Right() buf[str(i + 1)]['y'] = bbox_2d.Bottom() return buf boxes = get_deserialize_data(pred)
検出結果の取得ができました!
boxesには検出した物体や位置座標の情報が格納されています。
# boxesの中身 {'1': {'C': 0, 'P': 0.15625, 'X': 158, 'Y': 163, 'x': 181, 'y': 200}, '2': {'C': 0, 'P': 0.125, 'X': 3, 'Y': 12, 'x': 197, 'y': 158}}
・C : 検出された物体の番号
・P : 精度
・X.Y : 検出された物体の位置座標(左上)
・x, y : 検出された物体の位置座標(右下)
検出結果の見方については後ほど説明します。
画像に検出結果を重ねて表示させたら完成です!
for key in boxes: box = boxes[key] print(box) cv_img = cv2.rectangle(cv_img, (box["X"], box["Y"]), (box["x"], box["y"]), (0, 255, 0), 1) cv2.putText(cv_img, text =f"{box['C']} : {box['P']:1.3f}", org=(box["X"], box["Y"]), fontFace=cv2.FONT_HERSHEY_SIMPLEX,fontScale=0.5,color=(0, 255, 0),thickness=2,) plt.imshow(cv_img)
検出結果を実際にみてみましょう!

詳細を見ていきます。
結果の見方
緑の枠が検出された物体の位置を示しており、バウンディングボックス(以下、BBOX)といいます。
BBOXの上には検出された物体と精度が記載されています。左が検出された物体の番号で、割り当ては画像に記載の通りです。右が精度で、0-1の範囲の数値をとり、1に近い方が精度が高いと判断できます!
検出結果の取得ででてきたboxesには、検出された物体の番号、精度、BBOXの左上、右下の座標が格納されています。
検出結果
検出結果をみると、左上のボックスはケーブルを検出していますが、精度が0.125と低く、正しく検出できたとは言えません。
また、真ん中のボックスは紙コップを示しているかと思いきや、ケーブルと判定されており、こちらも正しく検出できていません。
ということで、今回作成したモデルではうまく検出ができませんでした、、、
一体どこが悪かったのか、、、
次回は、モデルを再学習させて精度向上に取り組みます!
この記事でAITRIOSを使った業務改善に興味を持たれた方はお気軽にお問合せください。 また、AITRIOSに限らず画像AIモデル構築のPoC支援も行っています。
詳しくは下記をご覧ください!
※AITRIOS、およびそのロゴは、ソニーグループ(株)またはその関連会社の登録商標または商標です。

データインテリジェンスチーム所属
元製造メーカー勤務。製品の不良検知を担当したことがきっかけとなり、データサイエンスに興味を持ちKDLへ。クラウドを利用したデータ活用に関してのトピックを中心に発信していきます。
