こんにちは!データインテリジェンスチームの吉田です。
今回は、TikTokと複数の大学が共同で開発した最新の単眼深度推定モデル「Depth Anything*1」について詳しく紹介します。
本記事は連載記事です。解説編と実践編の二部構成となっています!解説編ではDepth Anythingの論文についてちょっとした解説を行いたいと思います。論文の内容よりもまず動かしてみたい!という方は、この記事を飛ばして次回の実践編に向かっても構いません!
↓リンクはコチラ
要約
- Depth Anythingとは、多様なラベル付きおよびラベルなしデータセットを活用し、Zero-shotで動作可能な単眼深度推定モデル
- ラベルなしデータの効率的な学習と、事前学習したセマンティックセグメンテーション用の情報を保持することで汎化・高精度化を達成
- 単眼深度推定だけでなく、セマンティックセグメンテーションでも高精度化を達成
そもそも単眼深度推定とは?
単眼深度推定とは、単一のカメラ画像からシーンの深度情報(距離情報)を推測する技術です。通常、深度情報を得るためにはステレオカメラやLiDERなどの専用のセンサーが必要とされますが、単眼深度推定ではその名の通り、一つのカメラだけでこの情報を取得することを目指します。

弊社オフィスの一角を深度推定してみた結果がこちらになります。カメラからの距離が近いほど明るく、遠いほど暗くなっていることがわかります。
単眼深度推定は、さまざまな分野で応用が可能です。例えば、拡張現実(AR)の分野では、仮想オブジェクトが現実世界の物体に遮蔽されて見えなくなる効果を実現するときに利用されています。また、画像生成の分野では、深度情報を利用することで、物体の位置関係を保ったまま画像変換を行うときに利用されています。

https://github.com/lllyasviel/ControlNet-v1-1-nightlyより引用
画像左側の人物をポーズを維持したまま別人に変換している様子。
Depth Anythingとは?
ここからはDepth Anythingの解説です。Depth Anythingは、複数種のラベル付きおよびラベルなしデータセットで学習された、Zero-shotで使える単眼深度推定モデルです。これまでは自動運転やSLAMなど用途ごとにモデルを作成することが一般的でしたが、Depth Anythingは一つのモデルで対応が可能となっています。(すごい)
モデル構造
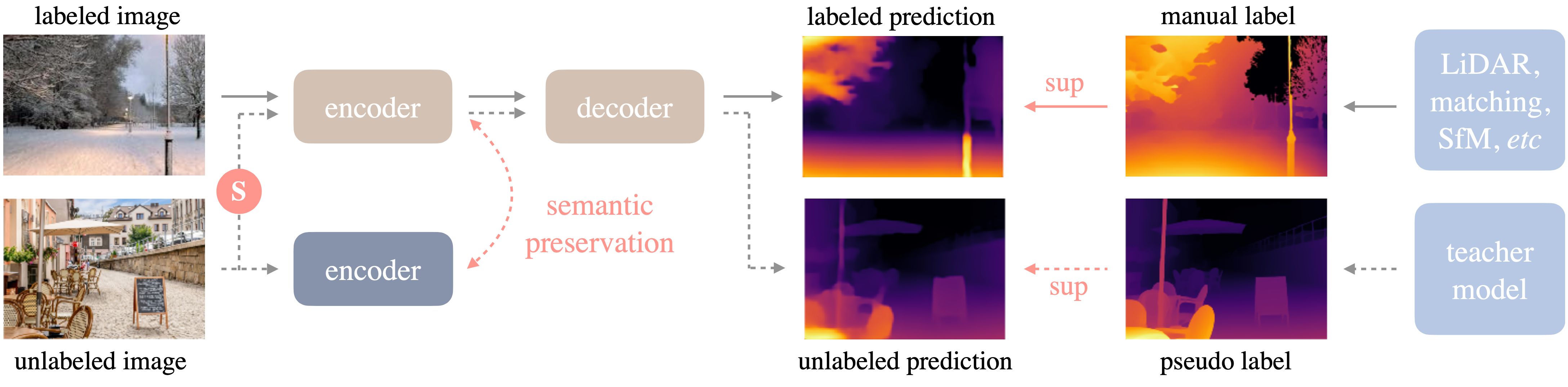
Depth AnythingはいわゆるEncoder-Decoder構造です。EncoderにDINOv2 *2、DecoderにDPT(dence prediction transformer) *3を採用しています。 また、学習時にはセマンティックセグメンテーションで事前学習したDINOv2を並列に動作させ損失関数の計算時に使用しています。(詳細は後述)
 https://depth-anything.github.io/より引用
https://depth-anything.github.io/より引用
学習に用いられたデータ
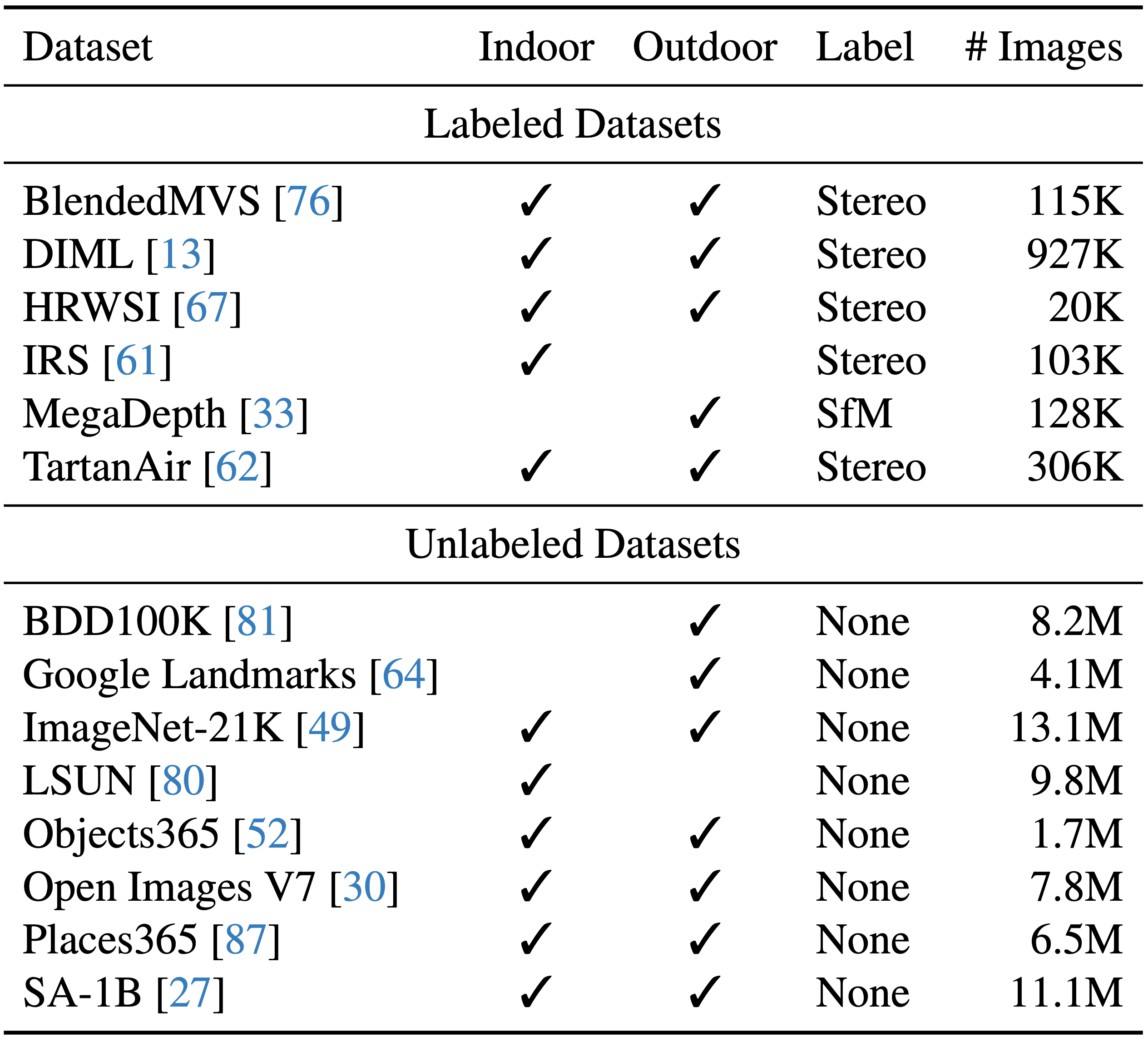
学習にはBlendedMVS・DIML・HRWSI・IRS・MegaDepth・TartanAirという6つのデータセットから約150万枚のラベル付き画像と、8つのデータセットから約6200万枚ものラベルなし画像を使用しています。 ラベル付きのデータは、Kinectv2などの深度センサーで取得したものやステレオマッチングで相対的な深度を求めたもの、ゲームエンジンであるUnrealEngine4を用いて3D空間をレンダリングし深度情報を生成したもの等の様々な方法で作成されており、その解像度や深度情報の精度といったものはバラバラです。これらを組み合わせて学習することで、よりロバストで汎用性の高い単眼深度推定モデルの学習を可能としています。
 https://depth-anything.github.io/より引用
https://depth-anything.github.io/より引用
学習時の工夫
ラベルなし画像学習時の工夫
Depth Anythingはまずラベル付きのデータセットを用いて教師モデルを学習します。次に教師モデルを用いてラベルなし画像に擬似ラベル(pseudo label)を付与します。最後に、ラベル付きのデータセットと疑似ラベル付きのデータセットを組み合わせたデータセットで生徒モデルの学習を行います。ここで、生徒モデルは教師モデルをファインチューニングするのではなく、より良い精度を得るために、生徒モデルはDINOv2の事前学習済みのモデルから再学習しています。
生徒モデルの学習時、疑似ラベル付きの画像に強い歪みを加えることでよりロバストな特徴を学習するような工夫がなされています。具体的には、ガウスぼかしなどを使って、強く色味を歪ませることと、画像分類のタスクでよく用いられるCutMix *4 を単眼深度推定に適応し、空間的に強く歪ませることです。これらにより、大規模なラベルなし画像からより多くの視覚情報を学習しています。
DINOv2のセマンティックな学習済み重みの保持
Depth AnythingはDINOv2のセマンティックセグメンテーションの事前学習済みモデルからのファインチューニングで学習されていますが、単眼深度推定への学習の過程で多くのセマンティックな情報が失われてしまうと考えられています。この問題に対処するために、Depth Anythingのエンコーダーの出力と重みを固定したDINOv2(セマンティックセグメンテーション)のエンコーダーの出力のコサイン類似度を計算し損失関数に加えています。また、コサイン類似度を計算するときにある程度の角度差を許容することで、Depth AnythingがDINOv2の持つセマンティックな表現と、データセットに含まれる深度情報の表現の両方をバランスよく学習することが可能となっています。
https://depth-anything.github.io/より引用
精度
単眼深度推定
(※指標の解説は省きます)
Depth AnythingはMiDaS*5と呼ばれる過去の最高モデルと比べて非常に高い精度を達成しました。なお、KITTIとNYUv2の2つのデータセットは、MiDaSの学習データに含まれていますが、Depth Anythingの学習データには含まれていません。それにも関わらず、Depth Anythingの精度が大幅に上回っているという点がDepth Anythingの精度の高さを物語っています。
 https://depth-anything.github.io/より引用
https://depth-anything.github.io/より引用
セマンティックセグメンテーションへの応用
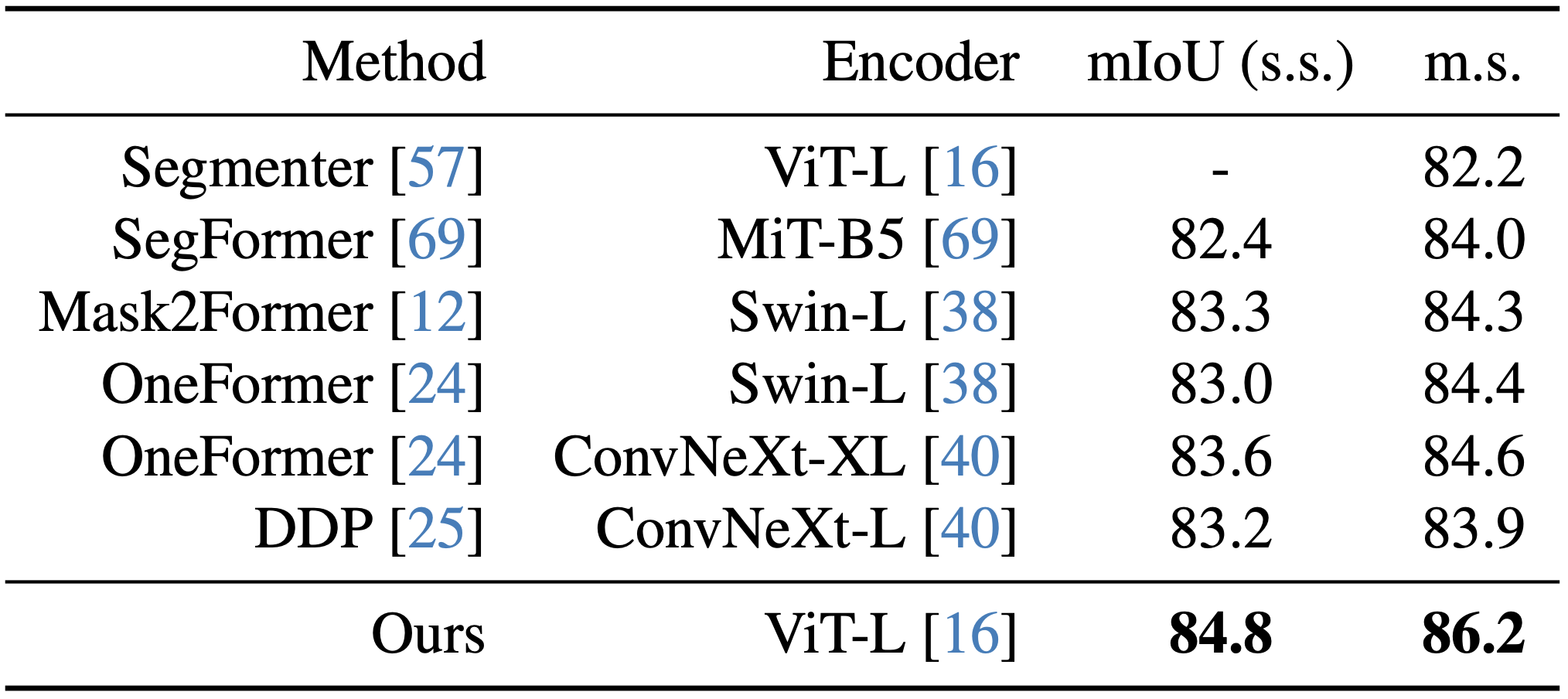
Depth Anythingのエンコーダーは、セマンティックセグメンテーションのタスクにおいても優れた性能を示しました。大規模なImageNet-21Kデータセットで事前学習された既存の強力なモデル、例えば、Swin Transformer*6やConvNeXt*7と比較しても、Depth Anythingのエンコーダーは優れた結果を示しました。この結果は、Depth Anythingは深度推定だけでなく、セマンティックセグメンテーションのような高レベルな視覚タスクにも有効な、汎用的な特徴表現を獲得できていることを示唆しています。
 https://depth-anything.github.io/より引用
https://depth-anything.github.io/より引用
まとめ
Depth Anythingの概要とその主な機能、学習方法、そして評価結果について解説しました。このモデルは、従来の深度推定モデルと比較して非常に高い精度と汎用性を持ち、さまざまな視覚タスクに応用可能です。次回は実践編として、このモデルを使った具体的な実行方法や応用例を紹介する予定です。どうぞお楽しみに!
参考
*1:Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data
*2:DINOv2: A Self-supervised Vision Transformer Model
*3:Vision Transformers for Dense Prediction
*4:CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features
*5:Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-shot Cross-dataset Transfer
*6: Swin transformer: Hierarchical vision transformer using shifted windows.
