データインテリジェンスチームの黒臺(くろだい)です。 どんな画像でもセグメンテーションができるというSegment Anything Model(以降SAMと表記)を今回は紹介します。
SAMとはMeta Platforms, Inc.(Meta)から発表されたセグメンテーションタスクに特化したモデルです。下記のURLから、ウェブサイト上でセグメンテーションを試すことができます。
segment-anything.com
セグメンテーションとは、画像内の物体を1ピクセルごとに分けるタスクを指します。画像内の物体のマスク用データを作ることと同義です。KDLの公式キャラクターのデジごんと背景を分ける場合、下記のイメージ通りになります。


このデモ画像のように、セグメンテーションとは画像内のものを分けることを指します。セグメンテーションをしたい対象物を選択し点を打つと、対象物のみを分けることも可能です。試しに、セールボートの画像に点を打ってみましょう。

ボートの底面から帆の部分まで正確にマスクできています。
ボックスで対象を指定してセグメンテーションも可能です。セールボートを長方形で覆ってみましょう。

SAMモデルはなぜこのように様々なものをセグメンテーションできるのでしょうか。今回は2本立てで紹介をします。本記事ではSAMのアルゴリズムを解説し、後編でPythonを使いセグメンテーションの実践をします。
SAMのアルゴリズムの構成要素
Meta公式の論文によると、SAMのアルゴリズムは大まかに三つのコンポーネントで構成されています。それぞれのコンポーネントの処理を解説します。
- 画像エンコーダ
- プロンプトエンコーダ
- マスクデコーダ
公式の論文は下記のURLから参照可能です。
Segment Anything
1.画像エンコーダ
画像エンコーダでは、高解像度の入力に適応したVision Transformer (ViT) をベースにしています。このエンコーダでは、画像を分割し、それらを1次元データに置き換え、それぞれのデータに位置情報を付与します。
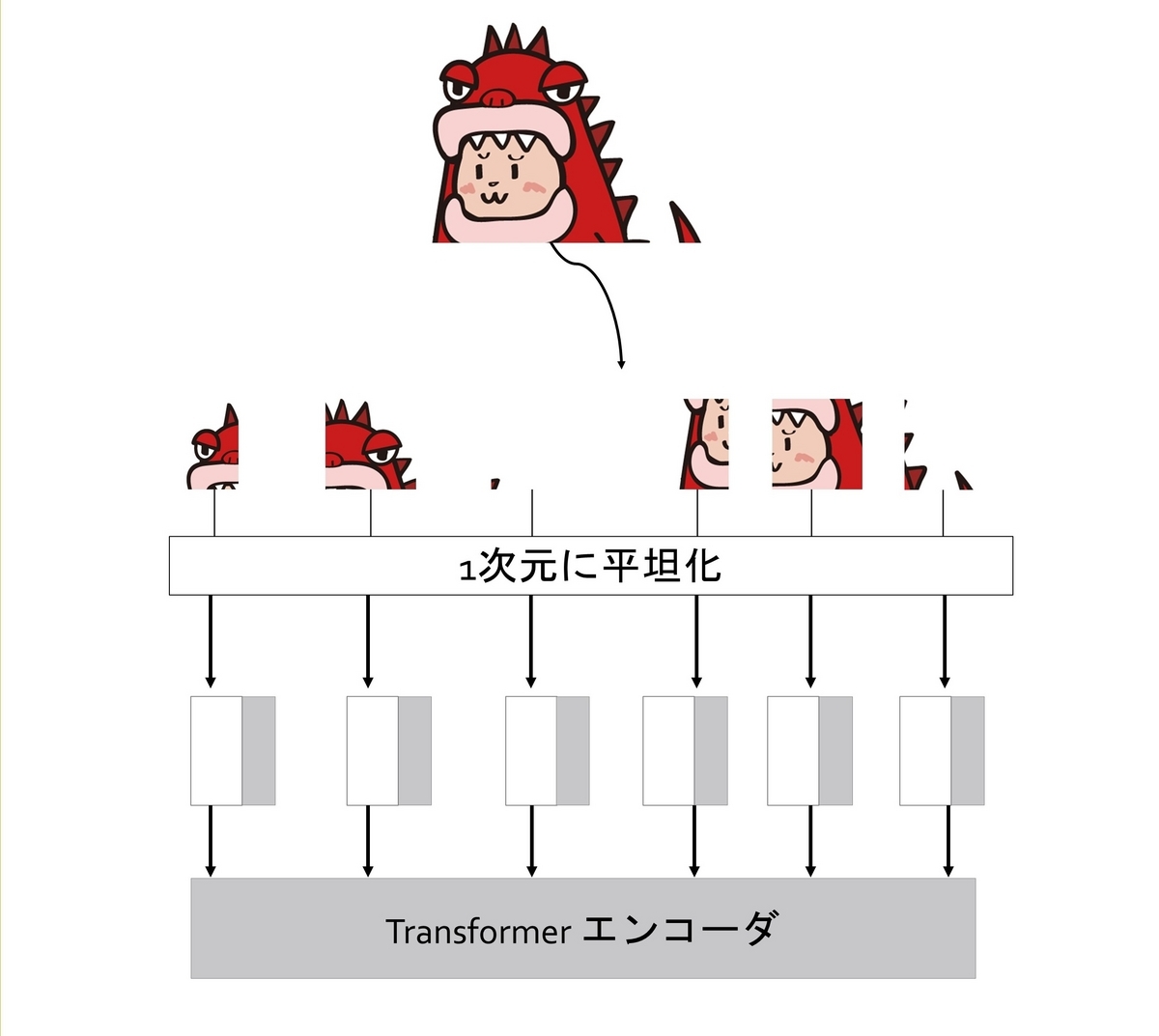
入力画像を低次元の特徴マップに置き換え、特徴抽出するためのコンポーネントです。
なお、ViTで行われるパッチの平坦化の解説は、株式会社Present Square様のDeepSquare Mediaの記事が詳細で分かりやすかったため、ご参照ください。
Vision Transformerはどのように画像を理解しているのか
2.プロンプトエンコーダ
冒頭のセールボート画像を思い出して下さい。SAMモデルでは、画像内に点を打つとセグメンテーションができましたね。ユーザが入力した情報を、プロンプトエンコーダでは解釈と同時にモデルが理解できる形式に変換をしています。
大まかに2種類の処理で、ユーザの入力を変換しています。
点・ボックス
ユーザが入力した指示を、位置エンコーディングを使い変換を行います。ここでは、画像内の特定の位置を理解するために活用されます。それぞれの指示は、学習された埋め込みと合算され、モデルが指示の種類を識別できるよう処理されます。テキスト
(※注※論文内では、テキストからセグメンテーションを行う機構を解説していますが、2024年6月26日時点ではコードが公開されていません。)
テキストの指示が入力された場合、CLIPをベースとして処理します。CLIPとは、言語と画像を数学的な手法で処理を行い、事前学習なしで画像の認識精度を行うモデルです。CLIPの特性と詳細な解説については、AGIRobots Blogの記事が分かりやすかったため、下記をご参照下さい。
CLIPの概要とAttentionとの関りについて解説!
CLIPを用いて、モデルは自然言語の指示を理解でき、画像のセグメンテーションが行われます。
3.マスクデコーダ
上記の画像エンコーダとプロンプトエンコーダからの情報を組み合わせて、マスクエリアを予測する処理です。
ここでは、アテンション機構を活用し、クエリと呼ばれる特徴収集用のベクトルを活用して画像のセグメンテーションを実施します。
アテンションの解説については、AGIRobots Blogの記事が分かりやすかったため、下記をご参照下さい。
Attention機構の起源から学ぶTransformer
他にもSAMモデルの強みとして、リアルタイムで動作すること、1つのプロンプトから複数の出力結果を生成できることがあげられます。こちらの性能については、後編の記事で紹介予定です。
SAMで使われたデータセット
SAMのアルゴリズムでは、ViT、CLIP、アテンション機構をベースとした応用がされています。
アルゴリズム以外では、大規模なデータを使い学習がされています。1100万枚の画像と、それらに付随した10億以上のマスクからなる〈莫大な〉データセットを使っています。画像のデータを確認しますと、人・乗り物・建物などを含んでいますね。

さすがMeta社が扱うデータセットです、取得したデータの撮影場所は全世界に広がっています。

このように世界中で撮影された大量のデータセットから学習することにより、高精度なセグメンテーションが実現しています。
まとめ
今回紹介をしたSAMモデルは、一般的な画像を対象としてセグメンテーションを高精度に行えます。人、町、建物などの画像であれば、十分活用できると判断できそうです。次回の記事では、Goolgle Colabを使い画像のSAMを利用したセグメンテーションを試します。
ぜひお楽しみに。
最後に
画像以外のデータ活用についても、課題の発見から解決方法の提案まで幅広くご相談を承っております。ご興味のある方はぜひお問い合わせください。
