株式会社神戸デジタル・ラボ DataIntelligenceチームの原口です。
今話題の「ChatGPT」とAzure Cognitive Servicesを利用して音声会話ボットを作ってみました!
本記事は連載記事となります。
- Step1:音声入力からテキストを生成する
- Step2:得られたテキストから返答を生成する
- Step3:返答を合成音声でしゃべらせる
今回は音声入力から得られたテキストをもとに返答を生成しましょう!
前回の記事はこちらからご覧ください。
返答の生成にはAzure OpenAIのGPTモデルを利用します。早速準備しましょう!
Azure OpenAIの準備
Azure OpenAIの利用には申請が必要です。
以下の記事を参考に申請・Azure OpenAIの準備を進めましょう!
Azure版ChatGPTで遊んでみる
準備が終わればAzure OpenAIへアクセスしましょう。今回はChatGPTで遊びたいのでプレイグラウンド→チャットを選択し下図の画面を表示しましょう。
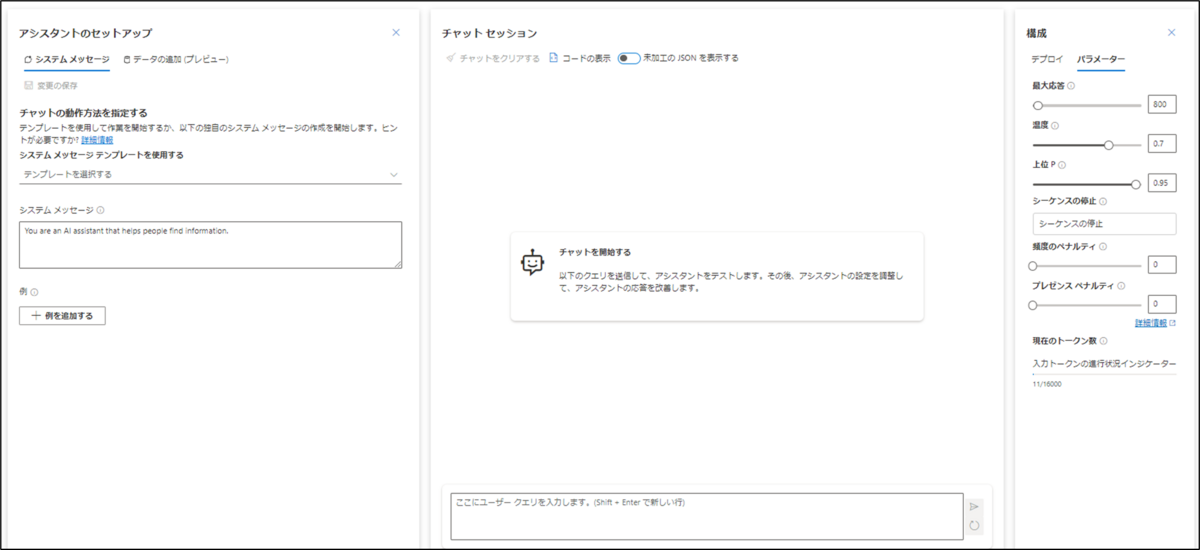
おいおいおい、普段使うChatGPTには無い機能が二つもあるやん・・・。ChatGPTって真ん中の「チャット セッション」だけじゃないのーーー!
ということで両側の見知らぬものが何者か見ていきましょう。Azure OpenAIのChatGPTの画面構成は要約すると次の画像のようになります。
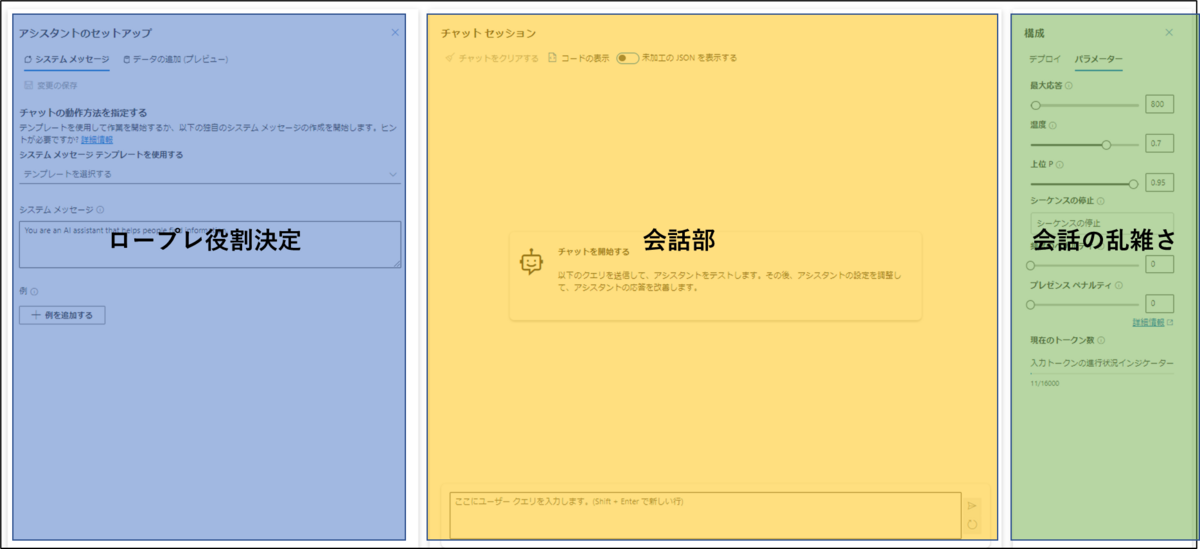
まずはアシスタントのセットアップから確認しましょう。
アシスタントのセットアップとは?
ChatGPTを利用する際に、以下のような様々な利用方法があると思います。
- 話し相手をしてほしい
- ブレインストーミングを手伝ってほしい
- プログラミングの補助をしてほしい
ChatGPTで上記を実現するにはチャットの一番最初に「あなたは○○です。XXのことについて△△してください。」のように指示を出しますよね。一度きりであれば手間になりませんが、同じ内容を別チャットに毎回入力するのはかなり面倒です。
そういった問題を解決してくれるのが「アシスタントのセットアップ」という機能です。上記の振る舞いの指示をシステムメッセージ部分へ記載しておくと、チャットがリセットされた場合でも常に同じ振る舞いをしてくれます。OpenAIのChatGPTにも実装して欲しい・・・。

実際にどの様な振る舞いをするか確認しましょう。
ロールプレイング設定:友達

流暢な関西弁をしゃべりますね・・・。こんな感じで会話の一番最初からロールプレイングに徹してくれます。
ロールプレイング設定:プログラミング補助

設定次第では会話だけでなくプログラミングを補助してもらうこともできます。どんな形式で出力して欲しいかを詳細に教え込んでおくことで自分好みの出力を取得することもできます。
このように、アシスタントのセットアップ部分を丁寧に作りこむことで理想のチャットボットを作ることができます。
ではもう一方のパラメータについて確認しましょう。
パラメータとは?
パラメータではChatGPTの出力アルゴリズムを調整できます。各値について簡単に確認しましょう。

- 最大応答数:モデルが応答する際に何トークンまで利用できるかを調節できます。長文などを入力したい場合はこちらを大きくすることが推奨されます。
- 温度:出力のランダム性を制御します。温度を上げると会話のランダム性が上がり人間に近い応答をします。温度を下げると決定論的な出力となり、同じプロンプトを入力した際に同一内容を出力しやすくなります。
- 上位P:温度同様に出力のランダム性を制御します。
- 頻度のペナルティ:同じテキストの出力を制限する際に利用します。
- プレゼンスペナルティ:これまでに出力したトークンを繰り返す可能性を削減します。
主に調整するのは温度・上位Pの二つになります。人間のように言葉遊びを実行してもらうには温度・上位Pを高くし、ロボットのように出力を安定させたい場合は低くします。
ここで温度・上位Pについて簡単に説明します。
温度・上位Pについて
今、「私はカレーが好きなのでお昼ご飯には」の続きを生成しています。この時、続く言葉の生起確率は以下の図だったとします。

ChatGPTはこの中から確率的に選択をします。確率が最も高いカレーが選択されることがほとんどですが、ごくまれに確率の低いパスタ・水が選択されることもあるということです。
この確率的な選択が人間らしい乱雑さを表現しているといえますね。
一方で同じ質問を投げてもたまに違う内容が返ってきてしまうと見ることもできます。実際、水は生起確率がものすごく小さいものの選択される可能性があるのですから。
こういった乱雑になってしまう問題を解決するのに温度・上位Pが利用されます。
まずは上位Pから。上位Pでは上位何%を選択の中に入れるかを調整します。

上位Pが1であれば確率上位100%が利用される、すなわちすべての単語から確率的に選択されます。
一方で上位Pが0.1であれば、上位10%が利用されるようになるので、確率の高いものの中から選択されるようになります。
このように上位Pを調整することで、選択の候補に挙がる単語を削ることが出来るため、結果的に同一の回答に近い物が得られるようになります。
一方温度は各生起確率自体を調整します。調整のイメージは次の通りです。

確率は総和が1なので、その範囲の中で調整が行われます。
温度が高い場合は確率が高いものと低いものをならすような動作をします。
一方で温度が低い場合は、確率が高いものをさらに際立たせるように動作します。
このように温度を変えることで生起確率そのものを操作できるため、温度を低くすれば一定の応答が見込め、温度を高くすればより表現豊かな会話を楽しめるようになります。
得られたテキストから返答を生成する
ではこれらの機能を使って返答を生成しましょう。Azure OpenAIの機能をPythonコードとして利用する際はチャットセクションにある「コードの表示」を選択しましょう。

これをコピペすれば応答が生成できる・・・???
では前回音声からテキストに変換した部分と組み合わせてみましょう。
import os import azure.cognitiveservices.speech as speechsdk import openai def from_mic(): speech_config = speechsdk.SpeechConfig( subscription="ここにキーを入れてください", region="ここにリージョンを入れてください" ) speech_config.speech_recognition_language = "ja-JP" speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config) print("Speak into your microphone.") result = speech_recognizer.recognize_once_async().get() print(result.text) return result.text def create_ans(text: str): openai.api_type = "azure" openai.api_base = "ここにURLを入れてください" openai.api_version = "2023-07-01-preview" openai.api_key = "ここにキーを入れてください" response = openai.ChatCompletion.create( engine="soukai", messages=[ {"role": "system", "content": "あなたは相談相手です。雑談対応をしてください。返答は手短に。"}, {"role": "user", "content": text}, ], temperature=0.7, max_tokens=800, top_p=0.95, frequency_penalty=0, presence_penalty=0, stop=None, ) return response["choices"][0]["message"]["content"] text = from_mic() ans = create_ans(text) print(ans)
Speak into your microphone. こんにちは。 こんにちは!どんな話題でお話しましょうか?
おおおおー!サンプルコード二つを連結しただけなのに会話になってる!これは夢が広がりますね!
まとめ
今回は音声会話ボット作成のStep2、得られたテキストから返答を生成する部分についてお話しました。
サンプルコードを少し組み合わせただけですが、かなり良いものになったと思います。
次回は最終回!いよいよ音声会話の実現です!お楽しみに!

データインテリジェンスチーム所属
データエンジニアです。画像認識を得意としており、画像認識・ニューラルネットワーク系の技術記事を発信していきます
