株式会社神戸デジタル・ラボ DataIntelligenceチームの原口です。
前回は、LeNetと呼ばれるCNNモデルをPyTorchで構築し、CIFAR-10というデータセットを用いて学習を行いました。 もう一度内容を確認したい方は、以下の記事をご覧ください。
今回は、学習したモデルの精度評価を行いたいと思います!
精度評価とは?
 精度評価とは何でしょうか?前回説明した通り、AI構築は上図のように進めます。
精度評価とは何でしょうか?前回説明した通り、AI構築は上図のように進めます。
学習フェーズと検証フェーズを基に導き出した最も良いと思われるパラメータの評価を行うことを精度評価(上図の評価フェーズ)と言います。
精度評価のフェーズでは「検証データから導き出した精度は、モデル本来の精度を評価出来るとは限らない」という点に注意が必要です。
AIは検証フェーズにて、検証データを用いてAIの精度を評価し、AIモデルの改善に役立てます。
つまり、検証データの分布の範囲内で精度を高くするように調整しています。そのため、検証データに対してのみ精度が高いモデルが構築される場合があります。
検証データと評価データの分布が一致している場合はある程度の精度が保証されます。しかし評価用データの分布が検証用データと異なっている場合は、検証精度がそのまま評価データに当てはまるとは限りません。
そのため、学習が終わった後&検証データに対してハイパーパラメータの調整が終わった後に、必ず一度だけ評価データを用いて精度評価を行いましょう!
精度評価をしよう!
それでは実際に精度評価を行っていきましょう!
まずは作成したモデルの保存です!
モデルの保存
前回の学習コードは、モデルの学習のみを行っていました。
今回は、一部を変更してモデルを保存できるようにしましょう!
適切なタイミングでモデルを保存しない場合、学習用データに過剰に適合したモデルが作成されるので注意が必要です!
model = BaseLineModel().to(DEVICE) criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters()) train_loss_list = [] val_loss_list = [] train_acc_list = [] val_acc_list = [] best_loss = None for epoch in range(EPOCHS): train_loss,train_acc = Train_Eval(model,criterion,optimizer,train_loader,DEVICE,epoch,EPOCHS) val_loss,val_acc = Train_Eval(model,criterion,optimizer,val_loader,DEVICE,epoch,EPOCHS,is_val=True) ## best_lossより小さなval_lossが出力された場合のみモデルを保存する。## if best_loss is None or val_loss < best_loss: best_loss = val_loss torch.save(model.state_dict(), './best_ckpt.pth') ################################################################# train_loss_list.append(train_loss) train_acc_list.append(train_acc) val_loss_list.append(val_loss) val_acc_list.append(val_acc)
best_lossは、学習時のval_lossの最小値を記録する変数です。
今回はbest_lossを下回るval_lossが出現するたびに保存されるようにしました。
モデルの保存には
torch.save(model.state_dict(), './best_ckpt.pth')
を利用します。
第一引数のmodel.state_dict()は、モデルの係数のみを指定しています。PyTorchではモデルを保存する際に、内部の係数のみを保存します。
第二引数にはモデルの保存場所と名前を記述します。今回は、現在作業を行っているディレクトリ直下に、best_ckpt.pthという名前で保存します。
ここまで準備ができましたら、再度モデルの学習を実行し、最適なモデルを保存しましょう!
学習経過の可視化
続いて学習経過の可視化を行います。
学習経過を可視化することで、モデルが汎化性能*1を獲得しているか大まかに確認することができます。
from matplotlib import pyplot as plt from random import randint, random ## 描画データの準備 x = list(range(100)) val_len = len(train_data) - train_len y1 = train_loss_list y2 = val_loss_list y3 = [x/train_len for x in train_acc_list] y4 = [x/val_len for x in val_acc_list] ## 損失のグラフ描画 fig = plt.figure(figsize = (20,10)) ax = fig.add_subplot(1, 2, 1) ## グラフのラベル・タイトルを設定 ax.set_title("loss") ax.set_xlabel('Epochs') ax.set_ylabel('Cross Entropy Loss') ## グラフをプロット ax.plot(x, y1,label="train") ax.plot(x, y2,label="val") ##凡例を描画 ax.legend() ## 精度のグラフ描画 ax = fig.add_subplot(1, 2, 2) ## グラフのラベル・タイトルを設定 plt.ylim([0,1]) ax.set_title("Accuracy") ax.set_xlabel('Accuracy') ax.set_ylabel('Cross Entropy Loss') ## グラフをプロット ax.plot(x, y3,label="train") ax.plot(x, y4,label="val") ##凡例を描画 ax.legend() plt.show()
実行結果は次の図のようになりました。
 左側が損失グラフ、右側が正解率のグラフです。まずは損失グラフから見ていきましょう。
左側が損失グラフ、右側が正解率のグラフです。まずは損失グラフから見ていきましょう。
損失グラフの評価
青線で描画されているtrainのグラフは終始低下していることが分かります。損失が低下するということは、正解との誤差が低下していることを意味しています。
一方、オレンジで描画されているvalのグラフを見てみると、20~40 Epochで最も損失が低下し、40 Epoch以降では損失が増加していることが分かります。
このvalの損失が増加している状況(40 Epoch以降)を過学習と言います。ここで過学習について説明します。
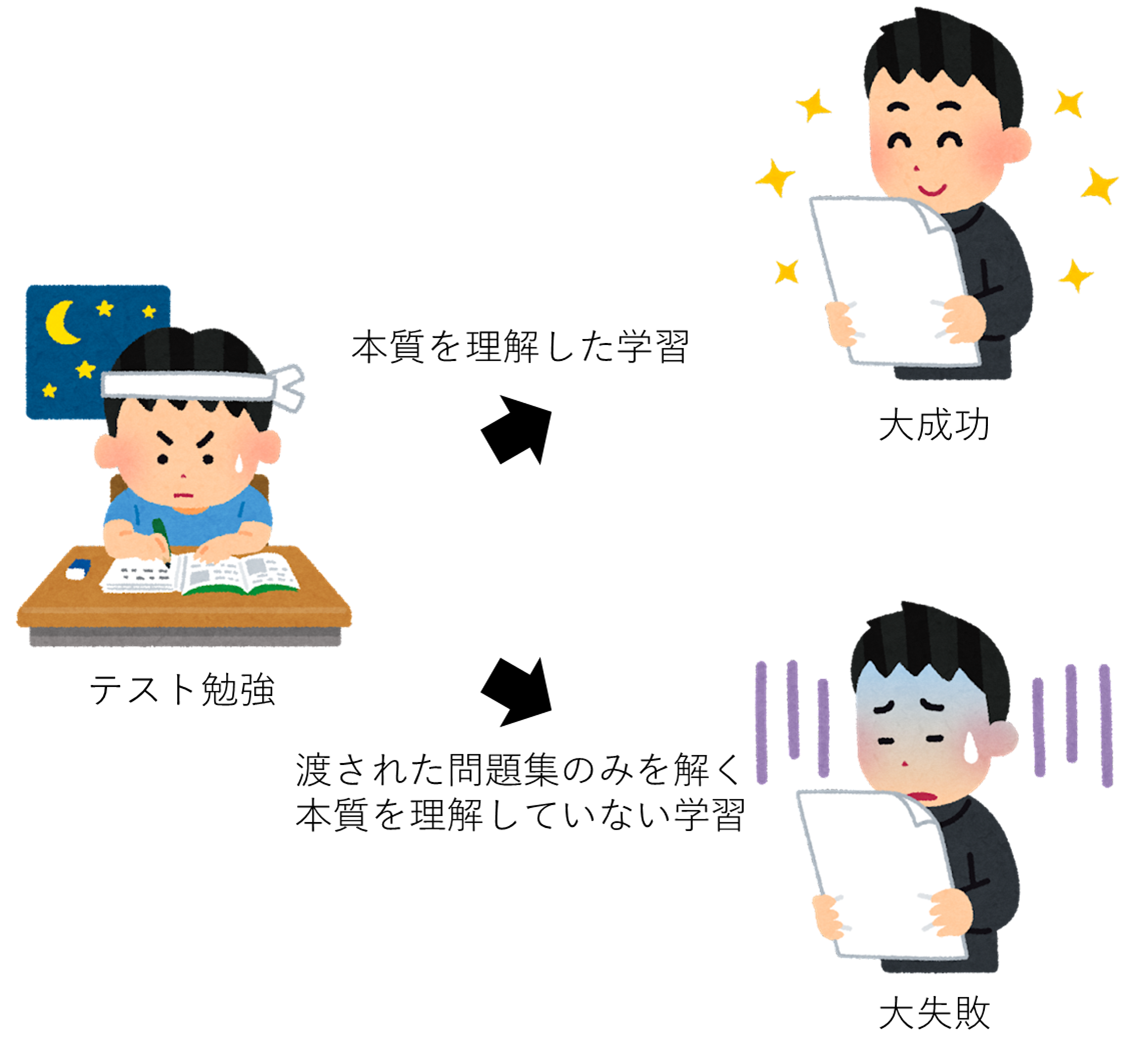 説明のために上図のような状態を考えます。読者の皆様も学生時代、テスト期間が近づけばテストで高い点数を取るためにテスト勉強をしたと思います。
説明のために上図のような状態を考えます。読者の皆様も学生時代、テスト期間が近づけばテストで高い点数を取るためにテスト勉強をしたと思います。
この「テスト勉強をする」という行動は、AIの学習段階と同様のことを行っています。
テスト勉強をする際、渡された練習問題のみを解くタイプと理屈から学び本質を理解してテストに臨むタイプの二通りの人が読者の皆様の周りにも居たのではないでしょうか。
理屈から学び本質を理解してテストに臨むタイプは、解き方やその意味を理解しているため、応用問題もしっかり解くことができます。
しかし渡された練習問題のみをひたすら解いてテストに臨むタイプは、問題の本質や理論を理解せずにテストを受けているため、テスト勉強した問題は解けても、応用問題は解くことができません。
渡された練習問題のみをひたすら解いてテストに臨むタイプの状態が、AIの過学習の状況です。
AIも学習用データを学習しすぎると、学習用データに特化し応用問題が解けないモデルへと変化します。
その結果、評価用データをうまく認識することができず、精度が落ちてしまいます。
こういった過学習の対策の一つとして、val損失が増加に転じた段階で学習をストップすることが挙げられます。
続いて正解率のグラフを見てみましょう。
正解率グラフの評価
こちらもtrainに関しては精度が向上していますが、valは20~40 Epoch付近から改善が見られません。
このように、trainとvalでグラフが大きく乖離していくのも過学習の傾向の一つです。
次は保存したモデルデータを読み出して、最も精度が良かった時のモデルの評価を行ってみましょう!
モデルの読み出し
モデルの読み出しは次のように行います。
#モデルの再定義 model = BaseLineModel().to('cuda') #学習済みモデルの読み出し model.load_state_dict(torch.load('./best_ckpt.pth')) #<All keys matched successfully>
前述した通り、PyTorchはモデル構造を保存していません。そのため学習済みモデルを利用する場合は、先にモデルの定義を行う必要があります。
モデルを構築したのちに、学習済みモデルを読み込みことで、正常に読み込むことができるのです。
テストデータに対する精度評価
それでは完全に未知の画像、テストデータに対して精度評価を行ってみましょう!
ワクワクしますね~~~!
正解率
まずは正解率から評価を行います。
from sklearn.metrics import accuracy_score label_list = [] pred_list = [] for data,label in test_loader: data = data.to('cuda') label = label.numpy().tolist() pred = torch.argmax(model(data),axis = 1).cpu().numpy().tolist() label_list += label pred_list += pred print(accuracy_score(label_list, pred_list)) # Test Data 10000 Correct 6139 Acc 61.4 %
正解率は61.4%ですね。ランダムに推論を行った際は10%なので、あてずっぽうではないことが分かりますね!
続いて、どのクラスの画像がどのクラスと間違っているか混同行列を用いて確認してみましょう!
混同行列による精度評価
from sklearn.metrics import confusion_matrix cm = confusion_matrix(label_list,pred_list) print(cm) #[[631 27 40 33 18 13 15 20 147 56] #[ 17 695 4 15 8 8 15 8 62 168] #[ 72 13 385 91 110 112 105 55 36 21] #[ 25 16 40 443 74 212 90 43 27 30] # [ 21 10 58 83 522 83 104 83 27 9] # [ 10 6 38 194 55 549 49 71 13 15] # [ 7 8 32 93 36 28 749 14 14 19] # [ 13 10 20 56 68 91 16 691 8 27] # [ 62 33 10 10 7 9 6 9 816 38] # [ 32 96 4 35 8 10 14 17 55 729]]
この表記だと分かりにくいですね・・・。少しカラフルに表現してみましょう!
# 混同行列を可視化 import seaborn as sns import matplotlib.pyplot as plt plt.rcParams["figure.figsize"] = (12, 10) glaph = sns.heatmap(cm) glaph.set( xlabel = "predict", ylabel = "label",xticklabels=class_list,yticklabels=class_list)

おお・・・!視覚的にわかりやすい!
ここで混同行列の見方について説明します!
画像左側、「label」と表されている軸が正解のラベルを表しています。画像下側の「predict」と表されている軸が予測結果を表しています。
「plane」が正解の画像に対して、モデルがどういった予測を行っているか確認したい場合は、「label」側にある「plane」の軸を横方向に見ることで確認することができます。
一方、「plane」をモデルが予測した際に、正解がどのようになっていたかを確認したい場合は、「predict」側にある「plane」の軸を縦方向に見ることで確認することができます。
混同行列の対角線上は、正解と予測が一致した回数を表しているため、対角線上の数値を見ることでモデルのおおよその得意・不得意を確認することができます。
今回のモデルでは、plane・car・frog・horse・ship・truckは比較的正しく予測できていることが分かります。
一方、bird・cat・deer・dogは上記のクラスと比較すると予測に間違いが多く出現しています。
catに関して、label側から見てみましょう。
plt.bar([x for x in range(10)], cm[3], width=0.5, linewidth=2, tick_label=class_list) plt.show()

上図から、間違えた中で最も多いのは「dog」だと分かります。犬と猫は形状も類似しているため、このようなミスが発生したと考察することができます。
このように、様々な軸から関連性を見つけることで、モデルの得意・不得意を探し出すことができ、次回の実験に役立てることができます。
まとめ
前回作成したモデルに対して評価を行い、以下の要点について学びました!
① 適切なタイミングでモデルを保存しよう!
適切なタイミングでモデルを保存しないと、学習用データに過剰適合したモデルが作成されるので注意が必要です。
②完成したモデルに対して、テストデータを用いて評価をしよう!
検証用データにたまたま適合したモデルで、実際のデータに対しては精度が出ないモデルも存在するので注意が必要です。
③モデルの得意・不得意も可視化するようにしよう!
可視化することで、なぜ間違えたのか・どうすれば改善するか?という次の手も考えやすくなります。
次回は、今回発生していた過学習を抑える「Dropout」について取り組んでいきたいと思います!

データインテリジェンスチーム所属
データエンジニアを担当しています。画像認識を得意としており、画像認識・ニューラルネットワーク系の技術記事を発信していきます
*1:汎化性能:はんかせいのう。 未知のデータに対する予測精度
